IS-FORTH
Scan&OCR: Kiss László
File-név: FORTH.ROM
Program neve: IS-Forth 1.1
|
Intelligent Software - 1985
rendszerbővítő, FORTH programozási nyelv |
TARTALOM
Bevezetés
 Az alábbi "rövid ismertető" a FORTH programozási nyelv, pontosabban annak - az Intelligent Software Ltd megvalósított- IS-FORTH rejtelmeibe kívánja bevezetni az olvasót. Az ismertető nem teljes, mindössze arra vállalkozik, hogy ízelítőt adjon a FORTH rejtelmeiből. A leírás Adorján Noémi - FORTH lépésről lépésre című könyve ( Műszaki könyvkiadó - 1990) alapján készült, az IS-FORTH "nyelvjárásához" igazítva.
Az alábbi "rövid ismertető" a FORTH programozási nyelv, pontosabban annak - az Intelligent Software Ltd megvalósított- IS-FORTH rejtelmeibe kívánja bevezetni az olvasót. Az ismertető nem teljes, mindössze arra vállalkozik, hogy ízelítőt adjon a FORTH rejtelmeiből. A leírás Adorján Noémi - FORTH lépésről lépésre című könyve ( Műszaki könyvkiadó - 1990) alapján készült, az IS-FORTH "nyelvjárásához" igazítva.
Néha nem is gondolnánk, hogy programgyűjteményünk egyes darabjaiban micsoda hatalmas" erők rejlenek. Közéjük tartozik az IS-FORTH Ha valaki legális úton jutott a rendszerhez, gyakran még az eredeti dokumentációval a kezében sem megy sokra: nehéz megtenni az első lépéseket Dokumentáció nélkül pedig végképp kudarcba fulladhatnak a FORTH-szal kapcsolatos kísérletek. Így könnyen hajlunk arra, hogy u egészet a sarokba dobjuk, pedig a FORTH igen komoly nyelv.
Más programnyelvekhez hasonlóan a FORTH-nak is több "nyelvjárása" létezik, ezek között néhány szabványos is van. Az egyik a FORTH 79, amelyet Leo Brodie ír le a "Starting Forth" című nagyszerű könyvben. Későbbi változat a FIG-FORTH 1.1. Ehhez hasonlítanak az itthon látott FORTH-ok, tehát ezzel fogunk foglalkozni (bár van újabb változat is, a FORTH 83). Az IS-Forth kimondottan Enterprise gépre készült, -az IS-Basic-hez hasonlóan- rengeteg (nem szabványos) funkcióval rendelkezik, amelyek jelentősen megkönnyíthetik a programozók életét.
A FORTH-ra legelfogultabb rajongója sem mondhatja, hogy könnyen tanulható. Előnyeit többek között annak köszönheti, hogy gépközeli nyelv (tehát használatához érteni kell egy kicsit a számítógép "lelkét"), hogy bővíthető, alakítható (tehát tudni kell valamennyire, hogyan működik maga a FORTH), és hogy sok benne az eredeti, szellemes, de nem feltétlenül könnyen érthető elgondolás. A FORTH megismerése tehát nem megy erőfeszítések nélkül. Mégis megéri, hiszen:
a FORTH olyan eszköz, amellyel rövid idő alatt lehet gyors, kis tárigényű és megbízhatóan működő programot írni, sőt, ez a munka még élvezetes is;
-
esetleg érdemes a számítógépről többet tudni, mint amennyi a BASIC, FORTRAN stb. programozáshoz szükséges;
-
a FORTH-szal együtt néhány igen szellemes programozási trükköt is megismerünk, ami jól jöhet még;
a FORTH teljesen más, mint a "megszokott" (magas szintű) programnyelvek (főleg, mint a BASIC). Edzhetjük vele egy fontos képességünket: hogy el tudunk fogadni a
megszokottól eltérő megközelítést is. (A számítógéppel foglalkozóknak erre nagyobb szükségük van, mint másnak.)
Mindenkinek, aki elszánta magát a FORTH tanulására, sok sikert és jó szórakozást!
1. Az első lépések
Indítsuk el a FORTH-ot! Az IS-Forth rendszerbővítő, tehát ha a gép bekapcsolása után nem az indulel, a :FORTH paranccsal indíthatjuk. A FORTH interpreter a forgalmazó cég, és a (BASIC-hez hasonlóan) rendszerben lévő és a programozó számára szabadon maradt memória kiírásával indul. Ezután várja, hogy adjunk neki egy parancssort. Addig vár, amíg a neki szóló sort be nem fejeztük.
Honnan tudja, mikor fejeztük be? Onnan, hogy lenyomjuk a sor végét jelző ENTER billentyűt. A begépelt sort az ENTER adja át a FORTH-nak; az ENTER lenyomásáig tehát más nem történik, mint az, hogy a FORTH ránk vár. Ezt érdemes megjegyezni, ha nem akarunk sok időt azzal tölteni, hogy az ENTER nélkül adott utasításaink végrehajtására várunk.
Az IS-FORTH-ban a BASIC-ben megszokott EXOS szerkesztő funkciók változatlanul működnek. Kezdjük úgy, hogy mindjárt be is fejezzük: adjunk egy üres parancssort: Nyomjuk meg az ENTER-t! A feleletként kapott OK azt jelenti, hogy a FORTH a mondottakat (esetünkben a nagy semmit) hiánytalanul végrehajtotta. Az OK után a FORTH a következő sor elejére várja újabb kívánságainkat.
Egy egyszerű szó, amit megért:
CR
Az OK ezúttal egy sorral lejjebb jelenik meg, a FORTH kiírt egy kocsivissza és egy soremelés karaktert. A Basic nyelvtől eltérően az IS-FORTH-ban az Interpreter megkülönbözteti a kis és nagybetűket! Minden parancsot nagy betűvel kell írnunk. Ha kis betű is szerepel egy szóban a Forth nem érti meg! A FORTH indításakor a billentyűzet nagybetűs-üzemmódba kerül. A "biztonság kedvéért" minden ENTER leütésekor, -ha esetleg megszűntettük a CAPS üzemmódot- a Forth ismét nagybetűs üzemmódba vált.
Hogy a hatás látványosabb legyen, írjuk most ugyanezt egy sorba többször! Ehhez azt kell tudnunk, hogy:
a szavakat nagybetűvel kell írnunk, az egyes szavakat egy soron belül (egy vagy több) szóközzel választjuk el egymástól.
Tehát, ha azt írjuk:
CR CR CR CR
a FORTH kiírja a négy üres sort és OK-val díjazza a szabályos feladatkiírást. Ha viszont azt írjuk, hogy
CRCR CR CR
akkor a FORTH az érthetetlen CRCR láttára megsértődik, és OK-ra sem méltatva minket, abbahagyja az egészet. A két "jó" CR-t már el sem olvassa. Játsszunk még "kiírósdit":
42 EMIT
Az EMIT szó kiírja azt a karaktert, amelyiknek a kódját megadtuk neki; a 42 a csillag kódja.
Definiáljunk egy csillagíró szót!
: CS 42 EMIT ;
Itt a kettőspont azt jelenti, hogy új szót definiálunk. A kettőspont is szó!! Így szóköz kell utána.
-
A kettőspont utáni CS (vagy bármi egyéb) egy név; így fogják hívni az új szót. A név bármilyen karaktert tartalmazhat, kivéve a szóköz, kocsivissza és backspace karaktert (ezeket a szavak elválasztására, a sor végének jelölésére, javításra használjuk).
-
Ami ezután jön (42 EMIT), az a cselekmény; itt írjuk le, hogyan fog működni az új szó.
A pontosvessző (ami szintén szó, tehát nem szabad "ráírni" az előtte állóra, sem közvetlenül "utána ragasztani" más szavakat) zárja a definíciót.
Ezzel megírtuk első FORTH programunkat. Most már ez is ugyanolyan FORTH szó, mint akármelyik másik, tehát nevének leírásával futtatható:
CS
Sőt, új szavak alkotására is felhasználhatjuk:
: PONT CR CS ;
: VONAL CR CS CS CS
Az új szavakkal pedig tovább építkezhetünk:
: F CR VONAL PONT VONAL PONT PONT PONT CR ;
Az új szavakat érdemes azonnal ki is próbálni. Így lehet (és ajánlatos) "biztosra menni". A FORTH egyik legvonzóbb tulajdonsága éppen ez: az építőkövek, amelyekből a program végül összeáll, megírásuk után azonnal, külön-külön is kipróbálhatók.
A FORTH alapszavak nagy része ugyanígy FORTH-ban íródott, más alapszavak felhasználásával. Például a
SPACE
szó, amely egy szóközt ír a képernyőre, így épül fel:
: SPACE 32 EMIT ;
A már ismert CR pedig így:
: CR 13 EMIT 10 EMIT ;
Ha a képernyőt már teljesen "összefirkáltuk", a
CLS
paranccsal törölhetjük le.
1.1. A szótárról
Mitől lett a CS, az F stb. végrehajtható szó? Mi történik, amikor ilyen "kettőspontos szódefiníciót" írunk?
A FORTH a számára értelmezhető szavakat egy szótárban tartja. Betöltés után a szótárban a FORTH alapszavak vannak. Új szavak létrehozásával a szótárat - vagy, ha úgy tetszik, magát a FORTH nyelvet - bővítjük. A szótári szavak neveit a
VLIST
(Vocabulary List; a vocabulary, ejtsd: vokébjulöri szó, jelentése: szótár) szóval írathatjuk ki a képernyőre. A VLIST hatására meginduló "szóáradat" a STOP billentyű leütésével megállítható. Ha saját szavakat definiálunk és utána VLIST-tel szemügyre vesszük a szótárunkat, látjuk, hogy a legutoljára definiált szavak jelennek meg legelőször; előbbi működésünk után például a szótárlista valahogy így kezdődik:
F VONAL PONT CS
A FORTH interpreter, mikor egy szót értelmezni akar, először is elkezdi azt a szótárban keresni. Mégpedig az útoljára definiált szónál; ebben talál adatot arról, hogy hol kezdődik az utolsó előttinek írt szó, így ha kell, ott folytatja a keresést, és így tovább.
Ha tehát példánkban az F definíciója után írunk egy újabb F szót:
: F 70 EMIT ;
akkor az F szót "átdefiniáltuk"; a FORTH figyelmeztető hibajelzést ad és beírja az új szót a szótárba.
Álljunk meg egy pillanatra!
Jó, jó, hogy a CS, F stb. attól végrehajtható, hogy benne van a szótárban. Beletettük, mikor definiáltuk őket. Az is igaz lehet, hogy az EMIT benne vart. Hiszen alapszó. De mitől van benne a 42 meg a 70? Csak nincs benne az összes szám? Ha pedig valami nincs a szótárban, akkor miért nem szól miatta az interpreter, miért tesz úgy, mintha minden a legnagyobb rendben volna?
Elvből. Az elv az, hogy ami nem szótári szó, az biztosan szám, tehát a FORTH interpreter a szótárban való sikertelen keresés után megpróbálja számnak értelmezni a kapott karaktersorozatot. Ha nem megy ("számszerűtlen" karakterek vannak benne), akkor az tényleg hiba. Ha viszont igen, számról van szó, akkor ez a szám a verembe kerül.
Mi legyen, ha ráuntunk a definícióinkra, nem akarjuk őket tovább használni? Például átdefiniáltunk egy szót, de megbántuk. A megoldás a FORGET (felejts) szó. A FORGET után (még ugyanabban a sorban) kell megadni az elfelejtendő szó nevét. Pl. ha a második F szavunkat vissza szeretnénk vonni:
FORGET F
A FORGET elfelejti a megadott szót, ezenkívül az utána definiált (tehát a szótárban "fölötte levő") szavakat. Micsoda??? Mindent, amit utána definiáltunk? Ez így van. Elvileg ugyanis bármelyik szóban, amelyet az elfelejtendő után írtunk, használhattuk ezt az éppen törölni kívánt szót! A FORTH szótár szavai egymásra épül(het)nek, nem lehet belőle csak úgy, "középről" törölni. (Meg lehet viszont őrizni szavaink fonásszövegét, hogy hogyan, arról lesz még szó. Most csak meg szeretnék nyugtatni mindenkit: nem kell majd egy hiba miatt mindig mindent újra begépelni!)
Melyik F szótól kezdve fog a FORGET felejteni, ha kettő is van? Szinte látatlanban meg lehet mondani: a "felsőtől", az utoljára definiálttól. A szavak keresése a szótárban, bármi célból történjen is, mindig felülről halad, ilyen irányban lehet a szótárat gyorsan végignézni. Ezzel példánkban kiássuk a régi, a csillagos F szót, és újra ez lesz az érvényes.
1.2. Mi a verem?
A verem (angol neve stack, ejtsd: sztek) igen fontos része a FORTH-nak. Ebben "leveleznek" egymással az egyes szavak. Például az EMIT a veremben keresi annak a karakternek a kódját, amelyet ki kell írnia a képernyőre; miután kiírta, le is pusztítja a veremről.
Azért hívják veremnek, mert több dolgot (esetünkben több számot) lehet benne tartani; ezek közül mindig csak egyhez férünk hozzá: ahhoz, amelyik legutoljára került oda, vagyis "legfelül van". Hogy ezt kitapasztalhassuk, egy új FORTH alapszót tanulunk.
-
Neve: . (azaz egyetlen pont karakter).
-
Működése: kiírja a képernyőre a verem tetején levő számot és egy szóközt tesz utána.
-
Hatása a veremre: a kiírt számot törli a verem tetejéről.
Próbáljuk ki!
65
.
A veremre tettük a 65-öt (első sor). -tal "rákérdeztünk" (második sor). Vissza is írta! Egyúttal törölte is. Győződjünk meg erről. Írjunk még egy pontot. Hibajelzést kapunk, amely azt jelenti, hogy több elemet akartunk a veremből elhasználni, mint amennyi volt benne.
És ha nem? Könnyen előfordulhat, hogy a Kísérletező Olvasó már egy csomó mindent művelt, mire ide eljut. Esetleg már volt a veremben valami. A verem kiürítésének legegyszerűbb módja: begépelünk egy szót, amelyről tudjuk, hogy a FORTH nem ismeri. A "feldühödött" interpreter kiüríti a vermet; ha ezután próbálja ki valaki a fentieket, meglátja, hogy így igaz. A módszer hasznos lehet, mikor véletlenül rakjuk tele a vermet "szeméttel". (Mondjuk ciklusban felejtünk el valami fölöslegeset törölni.)
Próbáljuk ki ugyanezt több számmal:
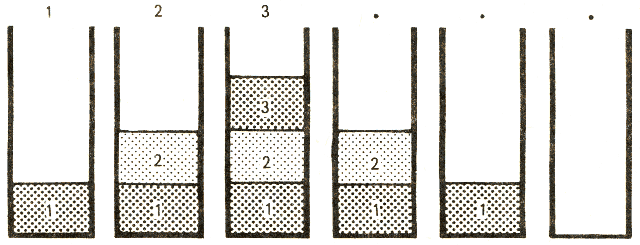
1 2 3 . . .
Melyik számot fogja először kiírni? Azt, amelyik a verem tetején van, tehát amelyik utoljára került a verembe. Ezt egyúttal törli is; a következő tehát az alatta levő elemet írja ki és törli. A kapott válasz:
3 2 1
Az egyes lépések után a verem a következő ábra szerint néz ki.
A legtöbb szó a veremben legfelül található számmal / számokkal dolgozik. Ezeket a számokat eközben gyakran kiveszik onnan, holott a későbbiekbenmég szükségünk lenne rájuk. Ezért szükség lehet a verembenlátható legfelső szám "lemásolásán", így a műveletet a másolaton hajtjuk végre, az eredeti a veremben marad. Ez a szó a:
DUP ( n - - - - n n )
Egyszerre akár két elemet is megduplázhatunk:
2DUP (n m - - - - n m n m )
1.3. Számolni tanulunk - kicsit szokatlan lesz...
Miből áll a FORTH aritmetika? Természetesen FORTH szavakból. Ezek nevei olyan rövidek, hogy a naivabbak műveleti jelnek is vélhetik. A négy alapművelet: + , - , * , / . Mindegyik a vermen várja a két számot, amelyeken a műveletet végzi (azaz a művelet két operandusát); ezeket le is emeli a veremről és helyükbe a művelet eredménye kerül. Erre a következő ábrán láthatunk példát.
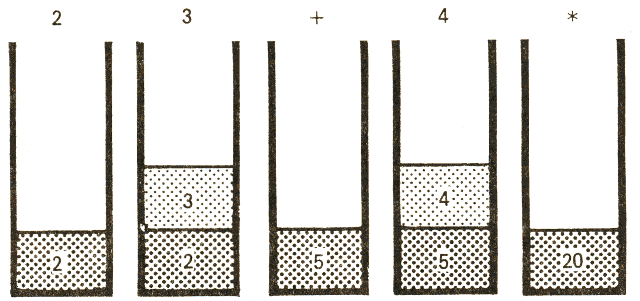
(Az adott lépés után a veremben levő adatokat rajzoltuk meg.) A
2 3 + 4 *
sorozat ugyanazt a számítást végzi, mint a (mondjuk) BASIC nyelven írt (2+3 )*4.
Az utóbbi, megszokottabb jelölésmódot infixnek nevezzük, szemben a FORTH (többeket visszariasztó) postfix jelölésével. Az elnevezések azt tükrözik, hogy a műveleti jel az infix írásmódban a két operandus között (in) van, a pontfixben pedig az operandusok után (post). A postfix megszokásához mankóul szolgálhat a következő:
Az operandusok sorrendje a postfix írásmódban ugyanaz, mint az infixben, csak a műveleti jel helye változik.
infix |
postfix |
1 + 1 |
1 1 + |
2 - 4 |
2 4 - |
6 / 3 |
6 3 / |
Ez azt jelenti, hogy pl. kivonásnál a szó a kivonandót várja a verem tetején, alatta pedig a kisebbítendőt. A művelet elvégzése után a veremben a különbség lesz. A tevékenységet a következő ábra szemlélteti:
| |
|
|
| |
|
kivonandó |
|
kissebbítendő |
különbség |
ilyen volt |
ilyen lesz |
Ezt a FORTH programoknál így szokás dokumentálni:
( kisebbítendő kivonandó - - - - különbség )
Zárójelet azért szoktunk írni, mert így az egyes szavak hatása a veremre a FORTH forrásszövegben is feltüntethető.
A ( ugyanis FORTH alapszó. Működése: a záró zárójelig "takarja" a szöveget, amelyet az interpreternek adunk; így a nyitó és záró zárójel közötti részt az interpreter el sem olvassa, nemhogy végrehajtaná. Tessék kipróbálni! A nyitó és záró zárójelnek egy sorban kell lennie. Így lehet FORTH-ban dokumentálni.
A veremhatás jelölésének sémája:
( előtte - - - - utána )
Ha az elemek sorrendjét nézzük, egyszerűen úgy kell képzelni, mintha a vermet jobbra döntenénk.
A négy alapművelet veremhatása:
+ | ( összeadandó1 összeadandó2 - - - - összeg ) |
- | ( kisebbítendő kivonandó - - - - különbség ) |
* | ( szorzandó1 szorzandó2 - - - - szorzat ) |
/ | ( osztandó osztó - - - - hányados ) |
A számolást segíti a következő néhány, az eddigiek alapján könnyen megérthető szó:
|
MIN | ( n1 n2 - - - - min ) |
A két szám közül a kisebbet adja. |
|
MAX | ( n1 n2 - - - - max ) |
A két szám közül a nagyobbat adja. |
|
MOD | ( n1 n2 - - - - mar ) |
Az n1/n2 osztás maradékát adja. |
|
/MOD |
( n1 n2 - - - - mar hany ) |
Az n1/n2 osztás maradékát és hányadosát is megkapjuk. |
|
ABS | ( n - - - - n1 ) |
Az n abszolút értékét adja. |
|
NEGATE | ( n - - - - n1 ) |
A kapott szám -1-szeresét adja. |
Számrendszerek
A FORRTH alapértelmezésben 10-es számrendszerben dolgozik, de bármikor megváltoztathatjuk a használt számrendszert:
BINARY - Kettes (Bináris) számrendszer.
OCTAL - Nyolcas (oktális) számrendszer.
DECIMAL - Tízes (decimális) számrendszer
HEX - 16-os (hexadecimális) számrendszer
A fenti szavak a veremre semmilyen hatást nem gyakorolnak, a BASE rendszerváltozóba töltik a megfelelő értéket (az OCTAL szó pl. 8-at). (Lásd 3.4. fejezet) Ha átállítjuk a használt számrendszert, a veremben tárolt értékek azonnal az új számrendszerben használhatóak a továbbiakban.
1.4. Összehasonlító és logikai műveletek
Hogyan hasonlítunk össze a FORTH-ban két számot? Természetesen az az első, hogy a veremre tesszük őket (így, mivel az operandusokat adjuk meg először, az összehasonlító műveletek írásmódja is postfix). Utána behívjuk valamelyik összehasonlító műveletet. Ezek a következők: < , > , =. Használatukhoz nem árt észben tartani, hogy:
az operandusok sorrendje a postfix írásmódban ugyanaz, mint az infixben, csak a műveleti jel helye változik.
A
2 3 <
művelet eredménye például az lesz, hogy a < egy igaz értékű jelzőt tesz a veremre.
A jelző
A jelző, angolul flag (ejtsd: fleg) arra való, hogy valaminek az igaz vagy hamis voltát jelezze. Ennek a két lehetőségnek az ábrázolására általában - így a FORTH-ban is - számokat használunk. FORTH-ban:
megállapodás szerint a jelző hamis, ha értéke 0, és igaz, ha bármi más.
Az összehasonlító műveletek "jól nevelt" jelzőket szolgáltatnak, amelyek értéke 0 vagy 1.
Írjunk egy szót amely arról tudósít, hogy mit gondol a klaviatúránál ülő felhasználó! A tudósítás a veremre tett jelzővel történik. A felhasználó lelkivilágában pedig a következő kérdéssel mélyedünk el: IGEN VAGY NEM?
Most várunk, amíg megnyomja valamelyik billentyűt. A vermen akkor adunk igaz értéket, ha a nagy 1 betűt nyomta le.
Ehhez meg kell tanulnunk azt a szót, amelyik kivárja, hogy valamelyik billentyűt megnyomják a billentyűzeten, s a billentyűnek megfelelő kódot a veremre teszi. Ez a szó a KEY ( - - - - kód ) (A KEY (ejtsd: kí) angol szó több dolgot is jelent, itt valószínűleg a "billentyű" fordítás a legtalálóbb.) A
KEY
után minden megáll, amíg meg nem nyomunk egy billentyűt. A képernyőn nem látjuk, mit nyomtunk meg (nem írja vissza, mint máskor), csak, hogy az interpreter OK-t küld. A karakterkód a veremben van - EMIT-tel kiírathatjuk a karaktert vagy .-tal (pont) a kódját..
Kicsit kényelmesebb, ha az ember látja is, hogy mit ír. Íme egy program, amely a KEY-hez hasonlóan bevárja egy billentyű lenyomását és a veremre teszi a megfelelő kódot, sőt még ki is írja a karaktert a képernyőre:
: ECHO KEY DUP EMIT ;
Ezek után az igen-nem program (figyelembe véve, hogy az I betű kódja 73) a következő:
: IVN CR ." IGEN,VAGY NEM?" ECHO 73 = ;
Az eddig látott adattípusok
Két, már ismert szó:
|
. | ( szám - - - - ) |
kiírja a vermen talált számot a képernyőre; |
|
EMIT | ( kód - - - - ) |
kiírja a vermen megadott karakterkódnak megfelelő karaktert a képernyőre. |
Mindkettő egy elemet használ a veremről. A verem egy eleme egy 16 bites gépi szó. (Gépi szó: 16 jegyű, 2-es számrendszerbeli - azaz bináris - szám, másképpen: egy 16 elemű, 0 és 1 értékeket tartalmazó sorozat.) A . ezen egy 16 bites, előjeles számot feltételez (látni fogjuk, hogyan lehet ennél hosszabb számokkal dolgozni), az EMIT pedig egy karakterkódot, amely egyébként elférne 1 byte-on (8 biten). Az EMIT a 2 byte-ból álló gépi szónak az egyik byte-ját egyszerűen figyelmen kívül hagyja!
Adott esetben például a vermen 42 hever (binárisan; ugyanis a veremben csak gépi ábrázolású számok vannak). Honnan lehet tudni, hogy ez "melyik" 42: előjeles szám, a karakter kódja, vagy - már tudjuk, ez is lehetséges - egy "igaz" jelző?
A FORTH-ban az adatok típusa csak attól függ, hogy milyen műveletet végzünk rajtuk.
A 42 tehát karakterkód, ha az EMIT használja, és előjeles szám, ha a . (pont)
42 EMIT * OK
42 . 42 OK
A + például előjeles számnak tekinti a verem felső két elemét. Ha valaki mégis a KEY-vel kapott karakterkódot felejti ott, az vessen magára.
A szó veremhatásának leírásakor az elemeket jelölő betűk az elemek típusát is közlik. Az eddig látott típusok:
c | karakterkód (character), |
n | 16 bites, előjeles szám (number), |
f | jelző (flag). |
Így dokumentáljuk az összehasonlító műveleteket:
< |
( n1 n2 - - - - f ) |
igaz a jelző, ha n1<n2; |
> |
( n1 n2 - - - - f ) |
igaz a jelző, ha n1>n2; |
= | ( n1 n2 - - - - f ) |
igaz a jelző, ha n1=n2; |
Igen hasznos szó, a
.S ( - - - - )
Mely kiírja a veremben lévő számokat, de nem távolítja el azokat. A kiírást a legalsó elemmel kezdi, és sorban kiírja valamennyi a veremben lévő számot. E parancs segítségével bármikor ellenőrizhetjük a verem tartalmát, anélkül, hogy bármit módosítanánk benne. Nagy segítség a tanuláshoz!
Miért kell egy jelzőnek "jól neveltnek" lennie?
Írunk egy szót, amely egy jelzővel közli, hogy a veremben talált szám 0 és 9 közé esik-e. A szó neve legyen 1JEGY, veremhatása pedig: ( n - - - - f ). Meg tudjuk már vizsgálni, hogy egy szám kisebb-e 10-nél (egész számokról lévén szó, ez ugyanaz, mintha a "nem nagyobb-e 9-nél" kérdésre válaszolnánk), és azt is, hogy nagyobb-e -1-nél. A két jelzőből egy ún. logikai ÉS művelettel kapjuk meg, hogy a két válasz egyszerre igaz-e.
A logikai ÉS két logikai értékből állít elő egy harmadikat: ha a két érték igaz volt, akkor a művelet eredménye igaz, egyébként hamis.A jelzők közötti ÉS műveletet az
AND
FORTH alapszóval lehet megvalósítani. (AND magyarul: ÉS.)
Vigyázat: az AND a logikai "és" műveletet a két operandus bináris alakjának minden egyes bitjével elvégzi! Ha p1. a veremben 2 és 1 volt, azaz binárisan
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0
és
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
akkor a logikai ÉS eredménye:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
vagyis 0 lesz, mivel az egymásnak megfelelő bitek közül az egyik mindig 0. Holott mi a 2-t is, az 1-et is igaz értéknek tekintjük, így az AND-nek a mi logikánk szerint igaz értéket kellett volna adnia.Erről a kényelmetlenségről (amely más alkalommal kényelem) tudnunk kell, pillanatnyilag azonban fölösleges miatta aggódnunk; az összehasonlító műveletek "jól nevelt", 0 vagy 1 értékű jelzővel kedveskednek, amelyekkel nem állhat elő a fenti félrekapcsolás.
: 1JEGY DUP -1 > SWAP 10 < AND ;
A másik fontos művelet a logikai VAGY, amely szintén két logikai értékből ad egy harmadikat. Az eredmény igaz lesz, ha a két logikai érték közül legalább az egyik igaz. Tehát akkor és csak akkor kapunk hamis-at, ha mindkét operaadus hamis volt. Láthatóan ez a VAGY nem felel meg a magyar nyelv VAGY szavának. Magyarul ilyeneket mondunk:
"Vagy láng csap az ódon, vad vármegyeházra vagy itt ül a lelkünk tovább, leigázva",
és ezt úgy értjük, hogy a két lehetőség kizárja egymást. Az előbbi VAGY-ot megengedő VAGY-nak hívjuk, hogy megkülönböztessük a magyar VAGY-ra jobban hasonlító kizáró VAGY-tól. A kizáró VAGY akkor ad igaz eredményt, ha a kapott logikai értékek közül az egyik igaz, a másik nem. VAGY-nak általában a megengedő VAGY-ot hívjuk, ha a kizáró VAGY-ra gondolunk, végigmondjuk a nevét. Ennek megfelelően a két FORTH szó:
OR (VAGY)
és XOR (eXclusive OR, Kizáró VAGY).
Ezek is bitenként működnek, mint az AND, de az összehasonlító műveletektől kapott jól nevelt" jelzőknél ez nem jelent különbséget.
Nézzük az 1JEGY-gyel ellentétesen működő TOBBJEGY ( n - - - - f ) szót, amely akkor ad igaz jelzőt, ha a kapott szám nem esik 0 és 9 közé (azaz kisebb 0-nál vagy nagyobb 9-nél):
: TOBBJEGY DUP 0 < SWAP 9 > OR ;
Az 1JEGY-gyel ellentétesen működő TOBBJEGY-et persze könnyebb úgy megírni, hogy felhasználjuk az 1JEGY-et. Egy olyan művelet kell hozzá (negálás, komplementálás), amely megváltoztatja a vermen levő jelző jelentését: az igaz jelzőből 0-t, a hamis, azaz 0 értékű jelzőből 1 -et csinál. Ez a szó nem szerepel a szabvány FIG-FORTH 1.1. alapszavak között, de az IS-FORTH-ban megvan, és megírni sem nehéz:
: NOT 0 = ;
Így a
: TOBBJEGY 1JEGY NOT ;
működése ugyanaz lesz, mint az előbb definiált másik TOBBJEGY-é.
1.5. Gyorsműveletek
A legtöbb számítógépnek gyorsan működő gépi utasítása van arra, hogy valamit 1-gyel növeljen vagy csökkentsen, 2-vel szorozzon vagy osszon, megvizsgálja az előjelét. Ehhez képest az a sorozat, hogy 1 + (tegyél a veremre 1-et, hívd a + szót) lassú és nehézkes. Az ún. "gyorsműveletek" levágják a felesleges kanyarokat, és körülményeskedés nélkül elindítják a megfelelő gépi utasításokat. A gyorsműveletek:
1+ |
( n - - - - n1 ) |
eggyel növeli n értékét; |
1- | ( n - - - - n1 ) |
eggyel csökkenti n értékét; |
2+ | ( n - - - - n1 ) |
kettővel növeli n értékét; |
2- | ( n - - - - n1 ) |
kettővel csökkenti n értékét; |
2* | ( n - - - - n1 ) |
megduplázza n értékét; |
2/ | ( n - - - - n1 ) |
megfelezi n értékét; |
0= | ( n - - - - f ) |
f akkor igaz, ha n = 0; |
0< |
( n - - - - f ) |
f akkor igaz, ha n < 0; |
0> |
( n - - - - f ) |
f akkor igaz, ha n > 0; |
Láthatóan a gyorsműveleteket végző szavak hasonlóan néznek ki, mint az ugyanúgy működő lépésenkénti parancsok, csak egy szóba írjuk az operandust a műveleti jellel; az 1+ szó ugyanazt a műveletet végzi, mint az 1 + sorozat, csak gyorsabban.
1.6. A verem átrendezése
A FORTH szavak elvárják, hogy a vermen a megfelelő sorrendben kapják a működésükhöz szükséges paramétereket. Ez nem mindig egyszerű. Időnként a paraméterek a veremben rossz sorrendben keletkeznek, lehet köztük felesleges, de az is előfordulhat, hogy valamelyikre még egyszer szükség lenne. Az ilyen gondok megoldására szolgálnak a következő szavak:
|
SWAP | ( a b - - - - b a ) |
megcseréli a két felső elemet; |
|
2SWAP | ( a b c d - - - - b a d c ) |
párban megcseréli a négy legfelső elemet |
|
DUP | ( a - - - - a a ) |
megduplázza a legfelső elemet; |
|
2DUP |
( a b - - - - a b a b ) |
megduplázza a két legfelső elemet; |
|
OVER | ( a b - - - - a b a ) |
a második elemről készít egy másolatot a verem tetején; |
|
2OVER |
( a b c d - - - - a b c d a b ) |
a harmadik, negyedik elemről készít másolatot a verem tetején; |
|
ROT |
( a b c - - - - b c a ) |
a harmadik elemet kiszedi alulról, és feldobja a tetőre; |
|
2ROT | |
az ötödik, hatodik elemet kiszedi alulról, és feldobja a tetőre; |
|
-ROT | ( a b c - - - - c a b) |
a ROT-al ellenkező irányba forgatja a verem legfelső három elemét.
|
| -2ROT | |
a két első elemet berakja az ötödik, hatodik helyre |
|
DROP | ( a - - - - ) |
eltávolítja a legfelső elemet; |
|
2DROP | ( a b - - - - ) |
eltávolítja a két legfelső elemet. |
|
NOT | ( - - - - 0 ) |
logikai hamis, azaz 0 értéket tesz a verembe |
Írjunk például egy olyan szót, amelynek hatása a veremre:
( X Y - - - - Z ), ahol Z = X * Y - (X + Y)
Nem kezdhetjük a dolgot aritmetikai művelettel, hiszen akkor elveszítenénk az x-et meg az y-t a veremről. Valamilyen módon konzerválnunk kell őket. Jó fogás erre az OVER kétszeri alkalmazása. Az egyes lépések mellett feltüntettük, hogy a lépés után mi lesz a veremben; ez a felírási mód igen hasznos, amíg nem válunk a verem rutinos bűvészévé. (Senkit ne zavarjon, hogy a definíciót több sorba írtuk!)
: XY
OVER
OVER
*
ROT
ROT
+
- |
( X Y ) (ez van a legelején a veremben)
( X Y X )
( X Y X Y )
( X Y szorzat )
( X szorzat Y )
( szorzat X Y )
( szorzat összeg )
( Z ) |
Hasznos, de nem szabványos szavak:
Van néhány veremkezelő FORTH szó, amely nincs benne a FIG FORTH alapszókészletben, az IS-FORTH-ban azonban szerepel:
|
DEPTH |
( - - - - n ) |
A szó (jelentése: mélység) a verem tetejére teszi a verem elemeinek (a DEPTH végrehajtása előtti) számát. |
|
PICK |
(n1 - - - - n2) |
A verem tetejére másolja a verem n1-edik elemét. A 2 PICK ugyanúgy működik, mint az OVER, az 1 PICK úgy, mint a DUP. |
|
ROLL |
( n - - - - ) |
Kiszedi a verem n-edik elemét és a verem tetejére teszi. A 3 ROLL a ROT, a 2 ROLL a SWAP szóval egyenlő hatású. A veremhatás szokásos jelölésével a ROLL működését csak pontatlanul írhatjuk le. |
1.7. Még egy szó a kiírásról
A
."
szó kiírja az utána megadott szöveget egészen a legközelebbi idézőjelig (") A záró idézőjelnek és a ." szónak egy sorban kell lennie! Az IS-Forth-ban elvetemült módon (valószínűleg programhiba) A ." szó csak szódefinícióban alkalmazva működik! Egy egyszerű példa:
: LOCSI-FECSI .CR ." EN VAGYOK AZ ENTERPRISE" CR ;
Nem szabad elfeledkezni róla, hogy a ." után szóközt kell hagyni! Így jelezzük, hogy a ." külön szó. A szóköz nem számít bele a kiírandó szövegbe.
Formázott kiírásra ad lehetőséget a
.R ( n m - - - - )
A szó n-et egy m szélességű mezőben jobbra igazítva írja ki.
1.8. Hogyan tároljuk programjainkat?
Eddigi próbálkozásainkban az a bosszantó, hogy a programok szövegei nem maradnak meg, nem lehet őket kijavítva vagy változatlanul újra felhasználni. Megtehetjük, hogy a programokat nem közvetlenül adjuk át az interpreternek, hanem valamilyen adathordozóra, az ún. screen-ekbe írjuk őket; itt bármikor javíthatók vagy elolvastathatók az interpreterrel. A screen (ejtsd: szkrín) szó magyarul képernyőt jelent, amit mi rövidítve kernyőnek fogunk nevezni.
A kernyő a szöveges információ tárolásának eszköze. Egy kernyőben annyi szövegnek van hely, amennyit egyszerre kezelhetünk a képernyőn.; ez a FORTH szabvány szerint 16 sor, egy sorban 64 karakterrel. Az IS-FORTH-ban egy kernyő 1024 byte (16*64). A szabvány FORTH egy lemezt egy szektorhalmaznak tekint, amelyet feloszt magának kernyőkre. Az IS-FORTH ún. kernyőfile-okat használ, ezzel lehetővé téve, hogy ugyanazon lemezen más file-okat is tárolhassunk. A file neve a kernyő száma lesz.
Az editor
A őrogramok szerkesztéséhez a beépített szövegszerkesztő használható. A szövegszerkesztőt a
EDIT ( n - - - - )
paranccsal indíthatjuk. Az n szám a szerkeszteni kívánt kernyő sorszáma lesz. (Pl. 1 EDIT parancs kiadása után az 1. kernyőt szerkeszthetjük.) A szerkesztés közben a szabványos Exos szerkesztő-funkciókat használhatjuk. Amennyiben az adott keryő-ben nem fejeződik be a program, a következő blokkot a
-->
Az editorból való kilépésre az ESC billentyű szolgál, ez a kilépés a módosításokat menti a buffer(ek)be. Kilépéskor a FORTH megadja a kernyőben felhasznált bte-ok számát. A szerkesztést bármikor a STOP billentyűvel megszakíthatjuk. (Szándékunkra rákérdz a gép.)
Programok kezelése
A kazettára mentéshez / betöltéshez a programnak nevet kell adni. Ezt a nevet a
NAME ( addr - - - - )
Változó tartalmazza. Ha több buffert akarunk kezelni (így több blokk mentése válik lehetővé egy adott néven), akkor a
BUFFERS ON
Szavakat használjuk. Amennyiben minden blokkot külön névvel kívánjuk használni úgy a
BUFFERS OFF
használandó. Ez utóbbi esetben a forrásszöveg egy blokknyi lehet.
|
SAVE-BUFFERS |
( - - - - ) | Adott néven szalagra / lemezre menti az aktuális blokkokat. |
|
LOAD-BUFFERS |
( - - - - ) |
Beolvassa szalagról a kimentett blokkokat. |
Ha megszerkesztettünk egy kernyőt, akkor a
LOAD ( n - - - - )
szóval átadhatjuk az interpreternek. (Lefuttathatjuk a programot.) A vermen a kernyő számát kell megadni. A LOAD hatására pontosan ugyanaz történik, mintha begépelnénk a megadott számú kernyőn található szöveget. Ha, mint többnyire, a kernyő definíciókat tartalmaz, akkor a betöltés, vagyis a LOAD hatására megjelennek a szótárban a definiált szavak. Ha több egymás utáni kernyőt akarunk betölteni, akkor a --> szót írjuk a kernyők végére. Betöltéskor ennek hatására az adott kernyő interpretálása abbamarad és a következő kezd el betöltődni. A
;S
szó hatására a kemyő interpretálása megszakad, az interpreter ott folytatja, ahol a LOAD volt.
Az interpreternek szinte mindegy, hogy az adott pillanatban billentyűzetről vagy kernyőről kapja-e a vezérlést. Azt a karakterfolyamot, amelyet az interpreter értelmez, az angol nyelvű irodalom input stream-nek nevezi, ezt itt befolyamnak fordítjuk.
Több kernyőt is betölthetünk egyszerre a
THRU ( n1 n2 - - - - )
szó, amely betölti n1-től n2-ig a screen-eket.
Egy kernyő szövegét a
LIST ( n - - - - )
szóval írathatjuk ki a képernyőre.
Megállapodás szerint minden képernyő legfelső sora tartalmaz valamilyen utalást a kernyő tartalmára. Ezt használja fel az
INDEX ( tól ig - - - - )
szó, amely nem szabvány ugyan, de az IS-FORTH alapszókészlet tartalmazza. Az INDEX kilistázza a megadott két szám közötti számú kernyők legfelső sorát és ezzel mintegy tartalomjegyzéket ad a kernyőinkről.
2. Vezérlési Szerkezetek
2.1. A feltételes utasítás
Tudjuk már, hogyan kaphatunk jelzőt egy feltétel igaz vagy hamis voltáról. Most megtanuljuk, hogyan lehet a jelzőket használni.
Az IF ... THEN
(A szabvány FORTH-ban IF … ENDIF szerkezetnek hívják) Az IF ... THEN szerkezet működése: az IF megeszi a verem tetején levő jelzőt. Ha a jelző igaz, az IF és THEN közötti programrész végrehajtódik, ha nem, nem. Mielőtt példát mutatnánk rá, gyorsan szögezzük le:
Valamennyi szerkezet, amely vezérlésátadást tartalmaz (tehát a feltételes és ciklus képző utasítások), csakis definícióban használható!
Írjunk egy olyan szót, amely ha 0 és 9 közötti számot talál a vermen, kiírja a képernyőre: EGYJEGYU . Természetesen felhasználjuk az előző fejezetben definiált 1JEGY ( n - - - - f ) szavunkat. Az új szó veremhatása: ( n - - - - )
: EGYJ 1JEGY IF ." EGYJEGYU" THEN CR ;
Más magas szintű programnyelvek a THEN-t teljesen másképp használják; mielőtt hagynánk magunkat megkeverni, legjobb, ha az eszünkbe véssük: ez más, a THEN itt ENDIF-et jelent! Az IF-et és THEN-et nem használhatjuk egymás nélkül.
Az ELSE
Ha nemcsak egy adott feltétel teljesülésekor vannak teendőink, hanem az ellenkező esetben is, akkor ilyesféleképpen építjük a programunkat.
|
IF | (itt van, amit akkor kell tenni, ha a jelző igaz); |
|
ELSE | (itt van, amit akkor kell tenni, ha nem) |
|
THEN | |
Például:
: EGYJ 1JEGY IF ." EGYJEGYU" ELSE ." NEM EGYJEGYU" THEN CR ;
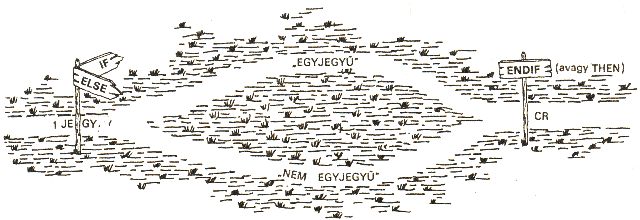
Olykor az ELSE ágon nincs más feladat, mint a jelzőről feleslegesen készült másolat eltávolítása. Hogy csak ennyiért ne kelljen ELSE ágat írni, van egy olyan FORTH alapszó, amely csak akkor duplázza a verem felső elemét, ha az nem 0.
?DUP
|
( n - - - - n n, ha n <> 0 )
( n - - - - n, ha n = 0 ) |
Egymásba skatulyázva
: EVES-VAGYOK
DUP
10 <
IF
." GYEREK"
DROP
ELSE
20 <
IF ." KAMSZ"
ELSE ." FELNOTT"
THEN
THEN
CR
; |
( n - - - - )
( n n )
( n f1 ) ( ha n<10 )
( n )
( n ) ( a kiírás kész, de a )
( veremben "szemét" maradt )
( n ) ( ha n >= 10 )
( f2 )
( ha 20 -nál kisebb)
( ha nem ) |
Az IF vagy ELSE ágon újabb, feltételtől függő teendőink lehetnek. Például írjuk egy EVES-VAGYOK ( n - - - - ) programot. amely -
n < 10-re GYEREK,
- 10 <= n < 20-ra KAMASZ
-
20 <=n-re FELNŐTT
Választ ír ki. Például a 3 EVES VAGYOK eredménye: GYEREK |
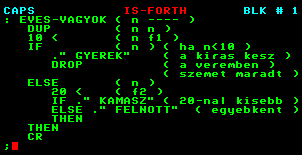
(A FORTH-ban mindegy, hol kezdjük írni a sorokat, pusztán az olvashatóság kedvéért érdemes az "összetartozó blokkokat" beljebb kezdeni.)
Figyeljünk rá, hogy a "belső" IF-es szerkezet mindig teljes egészében a "külső"-nek valamelyik ágán van! Ez kulcs ahhoz, hogy egy FORTH szövegben melyik IF, ELSE és
ENDIF tartozik össze. Ha látunk egy ilyesféle programrészletet:
IF A IF B ELSE C IF D THEN THEN ELSE E THEN
akkor ahhoz, hogy kiigazodjunk rajta, keressük meg a legbelső IF-et, és máris tudhatjuk, hogy az ENDIF-ek közül az utána leghamarabb jövő az övé! (Hasonló a helyzet a második legbelső IF-fel.) Láthatóan a második IF-nek ELSE ága is van.
IF
A
IF B
ELSE
C
IF D
THEN
THEN
ELSE E
THEN
vagyis úgy, hogy az összetartozó IF, ELSE és THEN egymás alá kerül, az adott ágon végrehajtandók pedig egy kicsit beljebb.
2.2. Indexes ciklusok
A visszatérési verem
A FORTH interpreter két vermet használ. Az egyiket már ismerjük: ez a számítási verem vagy adatverem, erre gondolunk, amikor egyszerűen csak veremről beszélünk. A másikat főleg maga az interpreter használja, legtöbbször arra, hogy ott jegyezze meg: egy szó lefuttatása (elugrás a megfelelő címre, az ott talált kód végrehajtása) után hova kell visszatérnie. Ezért visszatérési veremnek, röviden viremnek hívják. A virem programjainkban a verem útban lévő elemeinek átmeneti tárolására használható, ha szem előtt tartjuk, hogy
a virem elemeit minden szónak (amely a virmet nem szándékosan és ravaszul használja a vezérlés módosítására) ugyanúgy kell hagynia, ahogy találta; a virem állapota csak egy-egy szón belül változhat.
A virmet kezelő szavak (itt is, mint mindenütt a számítási veremre vonatkozó veremhatást dokumentáljuk):
|
>R | ( n - - - - ) |
A verem legfelső elemét áthelyezi a viremre. |
|
R> | ( - - - - n ) |
A virem legfelső elemét áthelyezi a veremre. |
Egy feladat, amelyhez jól jön a virem: írassuk ki a képernyőre a verem 4 eleme közül a legnagyobbat! A verem végső soron változatlan.
: .MAX
DUP >R
OVER MAX
SWAP >R
>R OVER >R
MAX
OVER MAX
.
R> R>
; |
( n1 n2 n3 n4 - - - - n1 n2 n3 n4 )
( n1 n2 n3 n4 ) ( a virem: n4 )
( n1 n2 n3 max3,4 )
( n1 n2 max3, 4 ) ( a virem: n4 n3 )
( n1 n2 n1 max3,4 ) ( virem változatlan )
( n1 n2 max1,3,4 )
( n1 n2 max )
( kiírás )
(n1 n2 n3 n4) (és a virem is az eredeti )
( állapotba kerül ) |
Lépegetés egyesével
A
DO ... LOOP
egy újabb szerkezet, amelyet csak szódefinícióban használhatunk. Ciklusszervezésre való; arra, hogy a DO és LOOP közötti programrészt (a ciklusmagot) ismételtessük vele. Ne felejtsük el, hogy a DO ... LOOP ciklusmagja legalább egyszer mindig végrehajtódik!
Például írjuk le 10-szer: ORA ALATT NEM ENEKELEK.
: HAZI-FEL 10 0 DO CR ." ORA ALATT NEM ENEKELEK" LOOP ;
A DO ... LOOP ún. indexes ciklus. Ez azt jelenti, hogy van valahol egy ciklusindex - röviden cindex - vagy ciklusszámláló, amely számolja, hogy a ciklusmag hányszor hajtódik végre. A cindex kezdőértékét és az indexhatárnak nevezett végértéket a DO-nak adjuk meg. A DO veremhatása: ( indexhatár kezdőérték - - - - ). A DO ezt a két értéket a viremre teszi. A ciklusmag futása alatt a virmen legfelül a cindex pillanatnyi értéke van, alatta pedig a ciklushatár.
Tudjuk, hogy a FORTH alapszavak egy része FORTH-ban íródott, még "alapabb" szavak felhasználásával. Ilyen a
SPACES ( n - - - - )
is, amely a vermen adott számú szóközt ír a képernyőre. A SPACES lényegében egy DO ... LOOP-ba tett SPACE.
Sok FORTH-ban, így az IS-FORTH-ban is a cindexet az
I
a külső cindexet (a virem harmadik elemét) a
J
szóval lehet előszedni. Mindkét szó veremhatása ( - - - - n ).
Lépegetés tetszőleges értékkel
Ha a ciklusban nem egyesével szeretnénk lépegetni a ciklusban a
DO ... +LOOP
Szerkezetet kell használnunk. Ez is indexes ciklus, azonban a +LOOP szóhoz érve annyit adunk hozzá a ciklusszámlálóhoz, amennyit előtte megadtunk a veremben.
Ne felejtsük, hogy a DO ... LOOP, DO ... +LOOP, IF ... ELSE ... THEN szerkezetek tetszés szerint egymásba ágyazhatók, de csak szódefinícióban használhatóak.
Kiszállás a ciklusból
Egy DO ... LOOP ciklust bármikor félbeszakíthatunk - a ciklusváltozó értékétől függetlenül Éppen ezt teszi a
LEAVE
szó. A Például írjunk egy BETU ( - - - - n ) szót, amely egészen az ENTER megnyomásáig karaktereket vár a billentyűzetről (az ENTER kódja 13), de legfeljebb 20-at. A BETU a vermen visszaadja a kapott karakterek számát, a szóközöket nem számítva. A karakterek bevárását és hasonlítgatását egy DO ... LOOP ciklusba tesszük. A ciklus futása alatt mindvégig ott lesz a vermen egy számláló, amelyhez 1-et adunk minden "valódi" karakternél.
: BETU
0
20 0 DO
KEY DUP EMIT
DUP 13 =
IF DROP LEAVE
ELSE
32 -
IF 1+
THEN
THEN
LOOP ; |
( ez lesz a számláló )
( ciklus 0-tól 20-ig )
( számláló kód )
( ha ENTER volt, )
( a kódra márn nincs szükség, kiszállunk )
( ha szóköz volt nem számoljuk )
( ha nem szóköz, növeljük a számlálót ) |
2.3. Index nélküli ciklusok
A végtelen ciklus (BEGIN ... REPEAT)
A
BEGIN ... REPEAT
szerkezettel a végtelenségig ismételtethetjük a BEGIN és AGAIN közötti ciklusmagot. Ilyen BEGIN ... AGAIN ciklusban fut maga a FORTH nyelven írt FORTH interpreter is. (Valahogy így fest: BEGIN Olvass be egy sort! Hajtsd végre! AGAIN.)
A végtelen ciklusnak is véget vethetünk, erre való az
EXIT
szó. . Nézzük, hogyan működik:
: EXIT R> DROP ;
például amikor így alkalmazzuk:
: BETUK (- - - - )
BEGIN
KEY DLIP EMIT 13 =
IF CR EXIT
THEN
REPEAT
;
Mikor a BETUK szó elkezd végrehajtódni, a virem tetejére az a cím kerül, ahol a BETUK végrehajtása után az interpreter folytatja a futást. Az EXIT-be való belépéskor az EXIT-ből (a BETUK-be) való visszatérés címe ennek tetejébe ül, de nem üldögél ott sokáig, mert az EXIT cselekménye éppen az, hogy őt onnan ledobja. Az EXIT tehát nem a BETUK-be tér vissza, hanem oda, ahova a BETUK-nek kéne, azaz a BETUK-et hívó szóba. Így lehet egy szó befejezését kikényszeríteni Az EXIT több FORTH változatban alapszó, a FIG-FORTH 1.1.-ben nem.
BEGIN ... UNTIL
A BEGIN ... UNTIL a két szó közötti ciklusmagot ismételgeti; a ciklusmag minden lefutása után az UNTIL megeszik egy jelzőt a veremről, eldöntendő, hogy visszamenjen-e a BEGIN-re, vagy menjen tovább. Az
UNTIL ( f - - - - )
a kkor folytatja a ciklust, ha hamis jelzőt talál.
Kiszállás a ciklus közepén
BEGIN ... WHILE ... REPEAT
A
WHILE ( f - - - - )
A veremről elhasznált jelző segítségével ellenőrzi, nincs-e vége a ciklusnak. A WHILE ( f - - - - ) akkor folytatja a ciklust, ha igaz jelzőt talál.
Az igaz jelzőre a WHILE továbbengedi a programot: végrehajtódik a WHILE és REPEAT közötti programrész, majd a REPEAT (feltétel nélkül) visszamegy a BEGIN-re. Ha pedig a WHILE hamis jelzőt talál, a program a REPEAT utáni szavakkal folytatódik. Például:
: TURELMES
BEGIN
CR ." KERSZ SPENOTOT? (I vagy N)?"
KEY DUP EMIT
73 -
WHILE
CR ." HELYTELEN VALASZ. PROBALJUK UJRA!"
REPEAT
CR ." ENNEK IGAZAN ORULOK!" CR ; |
( a vermen a válasz: egy karakterkód )
( a vermen akkor van 0, azaz "hamis", )
( ha I betűt nyomunk )
(ide akkor jutunk, ha nem I betű volt )
( innen visszamegy a BEGIN-re )
( ide akkor jutunk, ha végre )
(I betűt nyomunk ) |
3. Adattípusok
3.1. Előjeles és előjel nélküli értékek
Etessük meg az interpreterrel a következő parancssort:
65535
A kapott válasz
-1
Pedig mi nem -1-et tettünk a veremre. Vagy mégis? A 65535 16 biten ábrázolva:
1111 1111 1111 1111
A szó a vermen talált számot előjelesnek tekinti, azaz az első bitet előjelbitnek, és ha az 1, akkor a számot negatívnak. A negatív számokat úgy szokás ábrázolni, hogy a számot és ellentettjét ábrázoló két bináris sorozat összege 0 legyen. Ez 16 biten úgy megy, hogy a -1-et és 1-et jelentő szám összege 2^16 azaz:
1 0000 0000 0000 0000
(a magas helyértékű 1 már kicsordul a tizenhat bitből, maradnak a 0 jegyek). És valóban:
| |
1111 1111 1111 1111 |
|
+ |
1 |
| |
1 0000 0000 0000 0000 |
vagy, hogy az otthonosabb tízes számrendszernél maradjunk:
65535 + 1 = 65536= 2^16.
Mi lesz a túl nagy számokkal?
Látjuk, hogy 16 biten 2^16-1 = 65535-nél nagyobb szám nem létezhet. A nagyobb értékek első jegyei egyszerűen "lecsordulnak", elvesznek:
65536 = 0
(a bináris ábrázolás: 1 0000 0000 0000 0000).
65537 = 1
(a bináris ábrázolás: 1 0000 0000 0000 0001) stb. Hasonlóképpen a
35537 30000 + .
hatására is 1 a válasz. A FORTH a túlcsordulást nem kezeli, magunknak kell rá figyelni.
3.2. A duplaszavak
Ha egy szám nem fér el egy szóban, akkor ábrázolhatjuk kettőben, azaz: egy 32 bites duplaszóban. A duplaszó a vermen úgy helyezkedik el, hogy a magasabb helyértékű szava (az "eleje") van felül. Tehát pl. az 1 0 sorozattal egy 1 értékű duplaszót tettünk a verembe.
Erről a
D. ( d - - - - )
szó segítségével győződhetünk meg; ez kiírja a képernyőre a duplaszót, amely a verem két felső eleméből áll:
1 0 D. = 1
-1 -1 D. = -1
-1 0 D. = 65535
A kiíratott duplaszavak binárisan a következő ábrán láthatók.
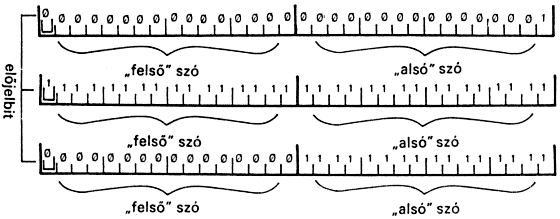
A D. szó nevében és a veremhatás jelölésében a d betű a doubleword angol szó rövidítése, bár akár a magyar "duplaszó" változaté is lehetne. Kevésbé körmönfont módon is lehet a verembe duplaszavakat csalni. Ugyanis:
azokat a számokat, amelyekben tizedespont van, az interpreter duplaszóba konvertálja.
Például:
100. D. = 100
10.0 D. = 100
10. D. = 0
Látjuk, hogy a veremre tett duplaszó értékét a tizedespont helye nem befolyásolja.
A duplaszavak éppúgy lehetnek előjelesek vagy előjel nélküliek, mint a szavak. Az előjel nélküli duplaszó jelölése a veremhatás leírásánál: ud. A veremhatás leírásában a d, ud jelölés duplaszót, azaz két elemet jelent.
Egy álcázott duplaszavas művelet
Szorzást és osztást kombinál a következő szó
/* ( n1 n2 n3 - - - - n4 ),
ahol n4 = (n1 * n2) / n3. Az n1*n2 szorzatot a */ duplaszóban tárolja, így nem fordulhat elő, hogy a szorzás túlcsordulást eredményezzen. Ugyanezt teszi a
*/MOD ( nl n2 n3 - - - - maradék hányados )
szó is, csak megkapjuk az osztás hányadosát is.
Az előjel nélküli, a duplaszavas és az előjel nélküli duplaszavas értékeket kezelő szavak:
|
U< |
( u1 u2 - - - - ud ) |
Előjel nélküli értékek összehasonlítása. f igaz, ha u1<u2 |
|
D. | ( d - - - - ) |
Kiírja a vermen talált duplaszót, utána szóközt. |
|
D.R | ( d n - - - - ) |
Kiírja a vermen talált duplaszót, egy n szélességű mezőben. |
|
D+ | ( d1 d2 - - - - d ) |
Duplaszavak (duplaszavas) összegét adja. |
|
D- | ( d1 d2 - - - - d ) |
Duplaszavak (duplaszavas) különbségét adja. |
|
D* | ( d1 d2 - - - - d) |
Duplaszavak (duplaszavas) szorzatát adja. |
|
DABS | ( d - - - - +d ) |
Duplaszó abszolút értékét adja. |
|
DMAX |
( d1 d2 - - - - max ) |
A két duplaszó közül a nagyobbat teszi a veremre. |
|
DMIN | ( d1 d2 - - - - min ) |
A két duplaszó közül a kisebbet teszi a veremre. |
|
DNEGATE | ( d - - - - -d) |
Duplaszót negál |
Jelölések:
- n - előjeles érték
-
u - előjel nélküli egyszavas érték (unsigned number)
-
d - Előjeles duplaszavas érték (doubleword)
-
ud - Előjel nélküli duplaszavas érték (unsigned doubleword)
E két utóbbi a vermen két elemet jelöl.
3.3. Ismerkedés a memóriával
Byte-os műveletek
A számítógép memóriája számozott és számukkal címezhető byte-ok sorozata. A FORTH memóriakezelő szavai ezeket a byte-okat szabadon olvashatóvá és felülírhatóvá teszik, függetlenül attól, hogy az interpreter kódjának közepén, a veremben vagy pedig valami "szelídebb" helyen vannak. A programozó dolga, hogy ne nyúlkáljon rossz helyekre. Egy jó cím a nyúlkálásra, ahol átmenetileg adatot tárolhatunk: az ún. pad (ejtsd ped). A pad szó jegyzettömböt, blokkot jelent. A pad címét a
PAD ( - - - - cím )
szó szolgáltatja.
Vigyázat! A pad a szótárterület fölött van, mégpedig állandó távolságra a szótár tetejétől (az utoljára definiált szó utáni byte-tól). Ezért mikor új szavakat definiálunk vagy felejtjük a régieket, a pad helye változik. Legjobb, ha a pad-be tett adatokat még ugyanabban a szóban felhasználjuk, amelyikben odatettük őket. Tartós adatmegőrzésre a változók szolgálnak, amelyekről a későbbiekben lesz szó.
A memória byte-jait kezelő szavak:
|
C@ | ( cím - - - - c ) |
a cím-en tárolt byte tartalmát adja meg; |
|
C! | ( c cím - - - - ) |
a c értéket a cím-en levő byte-on tárolja (a byte eddigi tartalma elvész). |
A veremhatás leírásában a cím memóriacímet jelent; típusára nézve ez egyszavas, előjel nélküli érték.
Szavas és duplaszavas műveletek
A memóriában nemcsak 8 bites, azaz byte-os értékeket tartunk, hanem szavasakat és duplaszavasakat is. Az erre szolgáló szavak:
|
@ | ( cím - - - - tartalom ) |
a cím-en és az utána következő címen levő 2 byte-ot, azaz szót teszi a veremre; |
|
! |
( n cím - - - - ) |
az n 16 bites értéket a cím-en meg az utána következő byte-on tárolja (a 2 byte előző tartalma elvész); |
|
2@ | ( cím d-tartalom - - - - ) |
a cím-en és az utána következő 3 byte-on tárolt duplaszót teszi a verembe. |
|
2! |
( d cím - - - - ) |
a duplaszót a cím-en meg az utána következő 3 byte-on tárolja (a 4 byte előző tartalma elvész). |
Tehát a
0 PAD 2!
sorral a PAD, PAD+1, PAD+2 és PAD+3 címeken levő byte-okat nulláztuk.
3.4. Változók és konstansok
Egy biztos hely: a változó
Vannak adatok, amelyekre időnként szükség lehet (a verem fenekének címe, a szótár tetejének címe, saját számlálóink), de nem mindig. Az ilyeneket nem tarthatjuk a vermen, mert belebolondulnánk, ha még ezeket is kerülgetnünk kéne, sem a padben, amelynek időnként megváltozik a címe. Erre vannak a FORTH-ban (is) a változók, amelyek ugyanúgy szótári szavak, mint az aritmetika vagy a ciklusszervezés szavai.
A FORTH változók úgy működnek, hogy a veremre tesznek egy címet; ezen a címen tárolhatjuk a 16 bites adatot, amelynek megőrzésére a változót létrehoztuk. A FORTH interpreter maga is használ változókat, ezek az ún. rendszerváltozók.
Példa a rendszerváltozóra: A BASE
A BASE (ejtsd: béz, jelentése: alap) változó a kiíráskor, beolvasáskor használt számrendszer alapszámát tartalmazza. Eddig ez mindig 10 volt. Ha mondjuk a 2-es számrendszerben akarunk dolgozni, akkor ennek a változónak az értékét 2-re állítjuk:
2 BASE !
Próbálgassuk, milyen az élet kettes számrendszerben:
1 1 + = 10
Nem, a 9-es számjegyet most nem veszi be az interpreter "gyomra", hiszen kettes számrendszerben vagyunk, ahol ennek semmi értelme. Meglepetten tapasztalja viszont a kísérletező Olvasó, hogy a 2, 3 számok - amelyek szintén "értelmetlenek", működnek:
2 . = 10
Ennek az az oka, hogy az első néhány szám benne van a szótárban; ezeket gyakran használjuk. Az interpreter munkáját gyorsítja, hogy "készen találja" őket, nem kell konvertálnia. A leggyakrabban használt két számrendszer a 10-es és a 16-os; ezek beállítására vannak FORTH alapszavak. Az is IS-FORTH-ban ezen kívül a 8-as és a 2-es számrendszerre is van szava. Működésük a forrásszövegükből világos:
: DECIMAL 10 BASE ! ;
: HEX 16 BASE ! ;
Hogyan tudhatjuk meg, hogy az adott pillanatban mi a konverzió alapszáma? Egyszerű, mondhatnánk meggondolatlanul, csak elő kell venni a változóból az alapszámot és kiíratni:
BASE @ .
Mit tudtunk meg ebből? Hogy a számrendszer alapszámát az adott rendszerben egy 1 és egy 0 jegy ábrázolja, vagyis hogy megegyezik a számrendszer alapszámával. Többre megyünk, ha az eggyel kisebb számot íratjuk ki:
BASE @ 1- .
Ebből a válaszból tudhatjuk, hogy pl. F, azaz 15 a legkisebb egyjegyű szám, ezek szerint a 16-os számrendszerben vagyunk.
Állítsuk most 5-re az alapszámot, és definiáljunk új szót az 5-ös számrendszerben:
5 BASE !
: KIIR 10 .
KIIR
Mi történik, ha a KIIR-t a 10-es számrendszerben próbáljuk ki?
DECIMAL KIIR
A kapott válasz. 5. A szótári szavakban binárisan vannak a számok, a KIIR definíciójakor
0000 0000 0000 0101
került oda, ez a tízes számrendszerben 5.
Írjunk egy .BASE ( - - - - ) szót, amely a BASE tartalmát decimálisan írja a képernyőre, de nem rontja el! (vagy pontosabban: elrontás után visszaállítja.)
: .BASE ( - - - - )
BASE @ DUP
DECIMAL
.
BASE !
;
Példa a rendszerváltozóra: Az OUT
Tudjuk már, hogy a képernyőre író FORTH alapszavak mind az EMIT-tel írják ki az egyes karaktereket. Az EMIT eggyel növeli az OUT (ejtsd: aut, jelentése: ki) változó tartalmát. Így, ha az OUT-ot nullázzuk, utána bármikor megtudhatjuk, hogy a nullázás óta hány karakter került a képernyőre.
Képzeljük el például, hogy egyforma sorokat akarunk egymás alá írni, amelyek két (előre nem tudni, milyen hosszú) számból állnak; azt kívánjuk, hogy az első szám a képernyősor 3., a második pedig a 13. pozíciójában kezdődjék. Feltesszük, hogy a két szám a vermen van. Megírjuk azt a szót, amely a fentiek szerint írja ki őket:
: TABULAL
CR
0 OUT !
3 SPACES .
13 OUT @ -
SPACES
.
;
|
( n1 n2 - - - - )
( " nullázzuk" az OUT változót )
( 3 szóköz, kiírjuk az első számot )
( 13-ra egészítjük ki a kiírt karakterek számát)
( kiírjuk a második számot ) |
Ú j változók létrehozása
Saját változókat a
VARIABLE ( n - - - - )
szóval definiálhatunk. A vermen várt érték a változó kezdőértéke. A változó nevét közvetlenül a VARIABLE után kell megadnunk:
0 VARIABLE SAJAT
Ezzel a SAJAT szó megjelenik a szótárunkban (mint arról VLIST-tel egy pillanat alatt meggyőződhetünk). Működése: a változó címét a veremre teszi.
Képzeljük el például, hogy listát készítünk a nyomtatón (a kimeneti csatorna állításával). Hogy mifélét, azt nem tudni, egy biztos: 60 sornak kell egy oldalon lennie. Új sort a listázóprogram mindig a CR szóval fog kezdeni. Definiáljuk át úgy a CR szót, hogy 60 soronként lapot dobjon (12 EMIT), és a laptetőre írja ki, hogy hányadik lapnál tart! Mivel nem tudjuk, mi történik listázás közben a veremmel, meg egyszerűbb is így, a sorokat és lapokat egy-egy változóban számláljuk:
0 VARIABLE SORSZ
0 VARIABLE LAPSZ
Mindkét változót eggyel kell majd növelgetnünk. Eddigi ismereteink szerint egy változó tartalmát valahogy így növelnénk 1 -gyel:
SORSZ @
1+
SORSZ !
A változókhoz (vagy bármely memóriaszóhoz) való hozzáadást egyszerűsítő FORTH alapszó a
+! ( n cím - - - )
amely a címen levő egyszavas értékhez hozzáadja n-et, és az összeget a cím-en tárolja. A +!-t valahogy így írhatnánk meg, ha még nem lenne:
: +! ( n cím - - - - )
SWAP OVER
@ +
SWAP
! ;
Ezzel növelhetjük a SORSZ tartalmát:
1 SORSZ +!
Sorok, lapok és egyebek számolgatásánál gyakran kell a változókat éppen 1-gyel növelni. Talán érdemes rá külön szót bevezetni, amely felhasználja az 1+ gyorsműveletet:
: INC ( cím - - - - )
DUP @
1+ SWAP !
;
A nyomtató programnak a következő dolgokat kell 60 sor kiírása után tenni:
: LAPDOB ( - - - - )
12 EMIT ( lapdobás )
0 SORSZ ! ( a sorszámlálás újrakezdése )
LAPSZ @ . (lapszám kiírása )
." lap" CR
LAPSZ INC ( a lapszámláló növelése )
;
A kiírást mindjárt lapdobással fogjuk kezdeni; ez a megfelelő pillanat a LAPSZ kezdőértékének beállítására is:
: ELSO-LAPDOB ( - - - - )
1 LAPSZ !
LAPDOB ;
A listázóprogram dolga lesz, hogy a listázást az ELSO-LAPDOB hívásával kezdje. Az átdefiniált CR:
: CR ( - - - - )
SORSZ INC (növeljük a sorszámlálót )
SORSZ @ 60 = ( lap vége? )
IF LAPDOB
ELSE CR
THEN
;
Konstansok
Ha egy értéket úgy akarunk megőrizni a szótárban, hogy soha nem változtatjuk, akkor egyszerűbb olyan szavakat használni, amelyek az értéknek nem a címét, hanem magát az értéket adják a vermen. Ezek a konstansok. Ilyenek például az 1, 2, 3 szavak, amelyek benne vannak a szótálban és az 1, 2, 3 értéket teszik a veremre.
Saját konstansainkat a
CONSTANT ( n - - - - )
szóval definiálhatjuk. A dolog meglehetősen hasonlít a változók definiálására. Például:
42 CONSTANT CSIL
ezzel a CSIL nevű konstans szót definiáltuk. A CSIL 42-t tesz a veremre.
3.5. Hol változik a változó? Ismerkedés a szótárral
A szótármutató
A FORTH programozás során a szótár mérete állandóan változik. Hogy éppen hol van a szótár "teteje", a szótár utáni első szabad hely, ahova a következő szótári szó kerül majd, azt az interpreter a DP (Dictionary Pointer, ejtsd: diksöneri pointer, jelentése: szótármutató) rendszerváltozóban tartja. A DP változó értékét sokat használjuk, ezért kiolvasására külön alapszó van:
HERE ( - - - - cím )
A szó forrásszövege:
: HERE ( - - - - cím ) DP @ ;
Már korábban volt róla szó, hogy a pad a szótár tetejétől állandó távolságra van. A jelenséget megmagyarázza a PAD szó forrásszövege:
: PAD ( - - - - cím ) HERE 68 + ;
Mi van a szótárban?
Egy szótárelem a következő részekből áll:
-
névmező: a szó neve;
- láncmező: mutató a szótár előző szavára (ha nincs előző szó, 0);
-
kódmező: mutató a kódra, amely a szó futásakor végrehajtódik;
-
paramétermező: a szó végrehajtásához szükséges többi adat (pl. változóknál a változó értéke).
A paramétermező --- teljesen önkényesen ,paramzőnek" rövidítjük - fizikailag a szó legvégén van. Így változó definiálása után a szótármutató pontosan az új változó paramzője mögé mutat. Ha ekkor a szótármutató értékét 1-gyel, 2-vel stb. növeljük, akkor ezzel megtoldjuk a változó paramzőjét 1, 2 stb. byte-tal. A szótármutató növelésére szolgáló alapszó, az
ALLOT ( n - - - - )
forrásszövege:
: ALLOT ( n - - - - ) DP +! ;
Hosszú változók
Ezzel a kezünkben van a lehetőség arra, hogy duplaszavas vagy hosszabb változókat definiáljunk.
87 VARIABLE DUPLA
88 HERE !
2 ALLOT

A DUPLA tehát két szavas, az első szó kezdőértéke 87, a másodiké 88. A paramzőbe való kezdőérték-tárolásra, egyúttal a paramző "tágítására" valók a következő alapszavak:
, ( n - - - - )
(vesző) Az n-et a HERE címen, egy szón tárolja, a szótármutató (DP) értékét 2-vel növeli.
C, ( C - - - - )
Az n-et a HERE címen, 1 byte-on tárolja, a szótármutató (DP) értékét 1-gyel növeli.
A két szó forrásszövege:
: , ( n - - - - )
HERE !
2 ALLOT;
: C, ( c - - - - )
HERE C!
1 ALLOT ;
Az előbbi sorozatot tehát így is írhattuk volna:
87 VARIABLE DUPLA 88 ,
Most már tudunk vektorokat, hosszabb adatsorokat definiálni. Fontos tudni, hogy erre vannak a FORTH-nak sokkal kényelmesebb eszközei is, itt csak azért definiálunk vektort, hogy jobban értsük a FORTH működését.
Definiáljunk például egy 10-elemű "szavas" vektort! Ennek paramzője 20 byte-os lesz; a
0 VARIABLE VECTOR
által definiált VECTOR 2 byte-os paramzőjét 18 byte-tal kell megtoldanunk:
18 ALLOT
A vektor úgy ér valamit, ha az elemeire külön-külön hivatkozhatunk. Megírjuk tehát az IK-ELEM szót, amely az elem indexét (sorszámát) várja a vermen, és a címét adja vissza:
: IK-ELEM ( n - - - - cím )
2* ( egy elem 2 byte )
VECTOR +
2 - ( az 1 indexű elem azon a címen kezdődik, amelyet a VECTOR ad )
;
Végül következzen négy ,a változók használatát segítő szó:
|
? | ( addr - - - - ) |
A változó címéről kiírja a változó értékét. |
|
0! | ( addr - - - - ) |
A változót nullázza. |
1+! | ( addr - - - - ) |
A változó értékét eggyel növeli. |
|
1-! | ( addr - - - - ) |
A változó értékét eggyel csökkenti. |
3.6. A FORTH -füzér és a WORD
A FORTH-füzérek
A szövegek, számok, amelyeket beolvasunk vagy kiírunk, a memóriában karakterfüzéreket alkotnak. (A karakterfüzér angol elnevezése string, ejtsd: sztring.) Egy ilyen füzérrel akkor tudunk dolgozni, ha ismerjük a kezdőcímét és a hosszát. A FORTH-ban gyakori tárolási mód: a füzért az ún. hosszúságbyte-tal kezdjük, amely a füzér hosszát tartalmazza, és ezután jönnek a karakterkódok. Az így tárolt füzért FORTH-füzérnek nevezzük. Ismerkedjünk meg a
COUNT ( ff-cím - - - - cím hossz )
alapszóval, amely a FORTH-füzér címéből előállítja az első karakter címét és a füzér hosszát (azaz a TYPE kiíró szó hívásához szükséges paramétereket)! A "LOVE" szót tartalmazó FORTH füzér byte-jai:
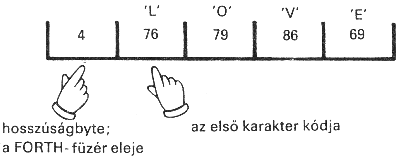
A COUNT szó forrása:
: COUNT ( ff-cím - - - - cím hossz )
DUP 1+
SWAP C@
;
FORTH-füzér alakjában szolgáltatja a szövegeket a FORTH interpreter egyik lelke, a WORD szó is.
Byte-sorozatokat kezelő, kényelmes alapszavak:
|
TYPE |
( cím hossz - - - - ) |
Kiírja a kimeneti eszközre (alapértelmezés szerint a képernyőre) a cím-en lévő karaktersorozatot, a megadott hosszon. |
|
CMOVE |
( honnan-cím hova-cím hossz - - - - ) |
Byte-sorozat mozgatása egyik címről a másikra. Az átvitel az alacsonyabb címeken kezdődik. |
|
FILL | ( cím hossz karakter - - - - ) |
A memóriát a cím-től kezdve hossz számú karakterrel tölti fel. |
|
ERASE | ( cím hossz - - - - ) |
A memóriát a cím-től kezdve hosz számú 0 byte-tal tölti fel. |
A WORD
WORD ( c - - - - )
(ejtsd: vörd, jelentése: szó) tördeli a befolyamot a vermen megadott határolókarakter alapján. Azaz: a WORD beolvassa a befolyam karaktereit, egészen a határolóig, átállítja a megfelelő rendszerváltozókat (hogy a legközelebbi WORD ott kezdje az olvasást, ahol ez befejezte), a beolvasott szöveget pedig FORTH-füzér formájában a HERE címre teszi. A WORD a sor végét mindenképpen határolónak érzi.
Egy példa a WORD alkalmazására a LEVEL szó, amelyet így lehet majd használni:
LEVEL KATINAK
DRAGA KATI, HALALOMIG IMADLAK
PITYU
avagy
LEVEL ELEONORANAK
DRAGA ELEONORA, HALALOMIG IMADLAK
PITYU
Lássuk a megvalósulást:
: LEVEL
32 ( a
: LEVEL
32
WORD
CR CR
." DRAGA"
HERE COUNT
3 -
TYPE
." HALALOMIG IMADLAK"
CR 20 SPACES
." PITYU" CR
; |
( a szóköz kódja)
( beolvassa a LEVEL után megadott nevet )
( az első szóközig, FORTH-fűzér formában )
( leteszi HERE címre )
( a fontos vallomásokat új sorban kezdjük )
( a vermen a név címe és hossza )
( "nak", "nek" nem kell ) |
A Kísérletező Olvasó esetleg kipróbálja a következőt:
32 WORD ABRAKADABRA HERE COUNT TYPE
és azt várja, hogy az ABRAKADABRA szót kapja válaszul, hiszen azt olvasta be a WORD. Ehelyett a TYPE szót fogja kapni, mivel az interpreter a parancssorok elemzésére maga is a WORD-öt használja, így, mire a TYPE végrehajtódik, az utolsónak végrehajtott WORD-őt rámolta a HERE címre.
Honnan ismerős? (WORD-del működő alapszavak)
A WORD-ben az a szokatlan, hogy nemcsak a veremről vesz adatot, hanem maga mögül, a befolyamból is kivesz egy szövegrészt és felhasználja. A jelenséggel már találkoztunk egyes FORTH alapszavaknál; ezek a szavak mind a WORD-öt hívják.
A legegyszerűbb ilyen alapszó a ( , amelynek a forrásával is megismerkedünk:
: ( 41 WORD ;
(41 a záró zárójel kódja). A nyitó zárójel beolvassa, amit maga mögött talál, egészen a záró zárójelig (vagy a sor végéig). A WORD úgy állítja át a megfelelő rendszerváltozókat, hogy az interpreter legközelebb a záró zárójel utánról olvasson; így a befolyanmak a két zárójel közötti része egyszerűen nem rúg labdába.
A másik alapszó, egy csökkent értékű változata:
: ." 34 WORD HERE COUNT TYPE ;
(34 az idézőjel kódja). A WORD beolvassa a befolyamot az idézőjelig és FORTH-füzér formájában elhelyezi a HERE címen; innen egy COUNT TYPE sorozattal kiíratható.
Mennyivel tud ennél többet az igazi szó? A különbség akkor látszik, mikor a szót definíció belsejében akarjuk használni. Az igazi a definícióban megadott szöveget írja ki, az itteni változat a definiált szó végrehajtódásakor olvassa el a befolyamból a kiírandó szöveget.
WORD-del olvassa be az elfelejtendő szó nevét a FORGET is. A WORD munkál minden olyan szó belsejében, amellyel más szavakat definiálhatunk:
VARIABLE CONSTANT ;
Pontosabban, a CREATE szó hozza létre az új szótárelemet, a CREATE pedig a WORD-del olvassa be a létrehozandó szótárelem nevét.
3.7. Számkonverziók
Megfelelő típushoz megfelelő kiíratás
A . .R D. egyöntetűen egy-két számjegy-előállító alapszóra épül. Ugyanezekkel az alapszavakkal mi is bármikor írhatunk hasonló szavakat, amelyek valamilyen formában kiírják a vermen levő, adott típusú értéket.
A vermen levő bináris érték kiírható számjegyekké konvertálását a
<#
szó kezdi el és a
#>
fejezi be.
A konvertált jegyeket előállító szavakat (#, #S, HOLD, SIGN) a <# hívása után, a #> hívása előtt futtathatjuk.
A konverzió során a memóriában létrejön a konvertált jegyekből és kiegészítő jelekből álló füzér, amelynek címét és hosszát a #> a veremre teszi (így TYPE-pal kiírathatjuk). Aki már próbált egy számot az egyik számrendszerből a másikba átírni, az tudja, hogy ez csak visszafelé, az utolsó jegytől kezdve megy. A konvertáló szavak is "visszafelé hordanak": a kiíratandó karakterekből álló füzér hátulról kezdve készül el. A füzér utolsó (elsőnek elkészülő) byte-ja a pad első byte-ja. (Ne csodálkozzunk tehát, ha a konvertáló szavak elrontják a pad elején tárolt adatainkat!) A
# ( ud1 - - - - ud2 )
szó beilleszti a füzérbe a (hátulról) következő jegyet. Működése: az ud1 előjel nélküli duplaszót elosztja a BASE tartalmával. Az ud2 hányadost a veremre teszi, hogy a konverzió folytatódhasson; kikalkulálja a maradékból a megfelelő számrendszerbeli számjegy kódját és beírja a füzérbe. A
#S
végigkonvertálja a vermen levő előjel nélküli duplaszót, annyi jegyet tesz a már előállítottak elé, amennyi szükséges (tehát értéktelen, vezető 0-kat nem). A vermen egy duplaszavas 0 marad. A #S forrása egyébként:
: #S ( ud - - - - dupla-0 )
BEGIN
# ( egy jegy )
OVER OVER OR 0 = ( a vermen heverő duplaszó 0? )
UNTIL ( ha nem 0 volt az utolsó duplaszó, folytatjuk )
;
A duplaszót, amelyben 3 konverzió részeredményeit tartottuk, a #> dobja el a veremről. A #, így a #S is a BASE-nek megfelelő számrendszerbeli jegyeket állít elő. A
HOLD ( c - - - - )
szó beírja a kapott c karaktert az eddig konvertált jegyek elé. Ha például duplaszavas, előjel nélküli számot akarunk úgy kiíratni, hogy az utolsó két jegy tizedesjegynek látszódjék:
: 2TJE
<#
# #
46 HOLD
#S
#>
TYPE
;
|
( ud - - - - )
( konverzió eleje )
( előállt a két utolsó jegy )
( tizedespont )
( további jegyek )
( konverzió vége ) |
Vagy, ha magunk szeretnénk a vermen megadni, hogy hány tizedesjegy legyen:
: TJE
<#
0 DO # LOOP
46 HOLD
#S
TYPE
;
|
( ud tizedesjegyek - - - - )
( konverzió eleje )
( tizedesjegyek )
( tizedespont ) |
Ha előjel nélküli, egyszavas értéket akarunk kiíratni, az sem gond. Könnyen csinálhatunk belőle kétszavasat, hiszen (pozitív számról lévén szó) a duplaszavas érték magasabb helyi értékű szava 0, egyszerűen ezt kell csak a veremre tenni. Erre szolgál az
U. (u - - - - )
Szó. Forrása:
: U. ( u - - - - )
0 ( a duplaszó magas helyiértékű szava )
<# #S #> ( a szükséges számjegyek előálltak )
TYPE SPACE
;
Többnyire azonban előjeles értékekkel dolgozunk. Ehhez meg kell ismerkednünk a
SIGN ( n d - - - - d )
szóval, amely szintén a <# és #> között használatos. A SIGN az a (azaz a verem harmadik eleme) előjelétől függően tesz a konvertált sorozatba mínuszjelet vagy sem. Példa a . szó lehetséges forrása:
: . ( n - - - - )
DUP ABS ( a felső példánynak nincs előjele )
0 ( könnyű belőle előjel nélküli duplaszót csinálni )
<# #S SIGN #>
TYPE SPACE
;
Végül egy szellemes példa Leo Brodie-tól, a STARTING FORTH című könyvből: Tegyük fel, hogy a vermen heverő duplaszó a másodpercek száma, és mi óra: perc :másodperc formában akarjuk kiíratni ezt az időtartamot. Lavíroznunk kell a 10-es és a 6-os számrendszer között.
: SEXTAL ( áttérés 6-os számrendszerre )
: OO
# ( egy decimális jel előállítása )
SEXTAL
# (egy "szextális jel előállítása )
DECIMAL
58 HOLD ( kettőspont )
;
A fenti programocska, ha jobban belegondolunk, a 60-nal való osztás maradékát írja ki, mégpedig tízes számrendszerben. (A hányadost pedig továbbadja a vermen.) Így a kívánt szót már könnyen megírhatjuk:
: SEC ( ud - - - - )
<# OO OO #S #> TYPE SPACE
;
4. A virtuális memória
Alapok
Mire ide eljut, az Olvasó bizonyára rengeteg programot út már. Nagy részüket kernyőre szerkesztette, hogy javíthassa őket. A kernyők az ún. virtuális memóriában vannak. A virtuális memória a memória kiegészítése lemezzel, lemezes kernyőfile-lal vagy kazettával. (A legutóbbi kicsit nehézkes, mert a FORTH virtuális memória kezelési elvei közvetlen hozzáférést igényelnek).
A virtuális szó itt látszólagosat jelent. A virtuális memória elnevezés azt tükrözi, hogy a virtuális memória blokkjait - bár adathordozón vannak - programozáskor úgy látjuk, mintha a memóriában lennének. Mégpedig azért látjuk úgy, mert a
BLOCK ( blokksorszám - - - - memóriacím )
szó gondoskodik róla, hogy a blokk, amelyre hivatkozunk, beolvasódjék a memóriába, ha eddig nem volt ott; a visszakapott címtől kezdve megtaláljuk a memóriában a blokk tartalmát. A blokk itt az olvasás-írás fizikai egységét jelenti, általában (lemezről lévén szó) egy szektort. A BLOCK szó:
-
beolvassa a memóriába a megadott sorszámú blokkot és visszaadja a beolvasott blokk címét;
-
vagy, ha a blokk egy előző beolvasás következtében már a memóriában van, akkor megkeresi és megadja a címét.
Az utóbbi esetben nem fordulunk a lemezhez; időt takarítunk meg anélkül, hogy erre programíráskor ügyelnünk kéne.
A virtuális memória blokkjait az interpreter a memória ún. blokkpuffereiben tartja. A BLOCK végignézi, hogy nincs-e a keresett blokk valamelyik blokkpufferben; ha megtalálta, akkor a blokkpuffer címét kapjuk, ha nem, akkor beolvas, de melyik pufferbe? A válasz egyszerű, ha van üres blokkpuffer. A blokkpufferek azonban kevesen vannak a virtuális memória blokkjaihoz képest. Többnyire valamelyik foglalt blokkpuffert kell felülírni. Mi történik ilyenkor a puffert foglaló blokkal? Elvész a tartalma, vagy visszaíródik az adathordozóra?
Ezt mi magunk döntjük el. Ha nem teszünk semmit, a puffer tartalma nem íródik vissza, tehát csak olvassuk a virtuális memóriát. Azt, hogy egy adott blokkot majd vissza is akarunk íratni, a blokkra való hivatkozás (BLOCK) után az
UPDATE ( - - - - )
szóval közöljük. Ettől az adott blokk "update-elt", vagyis módosított lesz. A szóhasználat egy kicsit félrevezető; a blokkpuffer tartalmát majd ezután fogjuk módosítani, az adathordozó blokkjait pedig még később, mikor a pufferre szükség van, vagy mikor minden módosított puffert visszaírunk.
Az UPDATE mindig arra a blokkra vonatkozik, amelyre a legutoljára hivatkoztunk a BLOCK szóval.
(Ez egyszerűen úgy történik, hogy a BLOCK leteszi a PREV rendszerváltozóba a blokk számát, az UPDATE pedig ott találja meg).
Az összes módosított blokkot a
FLUSH ( - - - - )
szóval írathatjuk ki (például, mikor felállunk a gép mellől). Ha viszont vissza szeretnénk csinálni mindazt, amit a blokkpufferekben elkevertünk, az EMPTY-BUFFERS ( ---- ) után tiszta lappal indulhatunk; az interpreter üresnek tekinti az összes blokkpuffert, anélkül, hogy egyet is visszaírna (vagy a blokkpufferek tényleges tartalmát megváltoztatná. Az
EMPTY-BUFFERS
nem a puffereket törli, hanem a pufferek nyilvántartását írja át.)
Hogy a virtuális memóriában tárolt szövegeket ugyanúgy végrehajtathatjuk az interpreterrel, mint a billentyűzetről beírtakat, az (többek között) azon múlik, hogy az interpreternek mindig a WORD adja át a következő interpretálandó szót. A WORD a BLK rendszerváltozó tartalmától függően működik:
Ha a BLK 0, akkor a billentyűzetről beolvasott parancssor következő szavát veszi elő. A parancssor tárolására szolgáló memóriaterület, a parancspuffer címe a TIB rendszerváltozóban van.
Ha a BLK nem 0, akkor a virtuális memória egy blokkjának számát tartalmazza; ebből a blokkból veszi a következő szót a WORD.
itt érdemes megemlíteni, hogy a parancsuffer címét a
TIB ( - - - - cím )
rendzserváltozó trtalmazza. A FORTH editorok gyakran az aktuális kernyő soraira vonatkozó műveletekből állnak. Az aktuális kernyő számát az SCR rendszerváltozó tartalmazza. Például a LIST is aktuálissá teszi a kilistázott kernyőt, azaz a számát elhelyezi az SCR változóban.
A BLOCK, az UPDATE, a FLUSH és az EMPTY-BUFFERS a virtuális memóriakezelés alapjai.
5. A szótár és a címinterpreter
Kettőspontos szavak
A FORTH programozás legalapvetőbb mozzanata: már meglevő szavakra új, célunkhoz közelebb vivő szavakat építeni, hogy később ezekre tovább építhessünk. Az ilyen, más szavakból összeállított szavak mutatókat tartalmaznak az őket alkotó szavakra; működésük lényege az őket alkotó szavak végrehajtása a mutatók alapján. A mutatóknak ezt a fajta kiértékelését egy pici, gyors programocska, az ún. belső interpreter vagy címinterpreter végzi. (Sok múlik azon, hogy a címinterpreter gyors legyen, hiszen a FORTH szavak végrehajtásakor nagyrészt ő fut.)
Ha egy szódefiníciót kettősponttal kezdünk, akkor ezzel azt közöljük, hogy az új szó régebbi szavakból fog felépülni. Így, mivel szótári szavak működését a kódmező tartalma határozza meg,
valamennyi, kettősponttal definiált szó kódmezőjében a címinterpreter címe van.
A mutatók, amelyeken majd a címinterpreternek tovább kell mennie, a kettőspontos szavak paramzőjében vannak; ezek a szót alkotó szavak kódmező-címe.
Így már megérthetjük, hogyan fejti vissza a kettőspontos szavakat a decompiler. Ha már eldöntötte, hogy kettőspontos definícióról van szó (a kódmezőben a címinterpreter címe van), végigmegy a paramzőn, s az ott talált kódmezőcímekből kiagyalja az összetevő szavak nevét. A kettőspontos szavak paramzőjében az utolsó kódmezőcím a ;S szóé; ez a szó küldi vissza a címinterpretert a hívó szóba. (A ;S hatására befejeződik a kernyő interpretálása.) A ;S kódmezőcímét a ; szó bűvöli bele az új szó paramzőjébe.
Primitívák
A FORTH szavak jó részét tehát a címinterpreter működteti: sorra elmegy a címekre, ahová a szó paramzőjében talált mutatók küldik. Ott esetleg újabb mutatókat talál, amelyeken továbbmehet. A sok küldözgetésnek egyszer vége kell, hogy szakadjon: előbb-utóbb valamelyik hívott szónak ki kell rukkolnia vele, hogy mit is kell csinálni. Ezeket a végső szavakat, amelyek tehát nem más szavakra utaló mutatókat, hanem végrehajtható gépi kódokat tartalmaznak, primitíváknak nevezzük. A primitívák kódmezőjében a mutató a primitíva saját paramzőjébe mutat. A paramzőben gépi kód van, ez hajtódik végre, mikor a primitívát futtatjuk. A primitívák létezése alapja az alábbi kijelentésnek:
Amit egy gépen lehet, azt a rajta futó FORTH-ban is lehet.
A primitívákat arra is felhasználhatjuk, hogy az operációs rendszer rutinjait hívjuk vele. Primitívák létrehozására az ASSEMBLER szótár szavai szolgálnak, ezek teszik lehetővé, hogy gépi kódok helyett mnemonikokat használjunk, hogy az assembler programozásban is a rendelkezésünkre álljanak a vezérlési struktúrák stb.
5.1. A Forth Assembler
Az IS-Forth olyan szótárat is tartalmaz, amely a Z80 assembler .programozást segíti. Olyan esetben, ha a kész programot (alkalmazást) fel kell gyorsítani, ezt úgy érik el, hogy a sebesség-kritikus részeket újraírják ("kihegyezik") Forth-assemblerben, majd az egész programot újrafordítják.
A Forth-assembler módba az
ASSEMBLER
paranccsal léphetünk be. Ettől kezdve Forth-assembler szavakat is használhatunk a FORTH szavak mellett. A "normál" FORTH-módba a
FORTH
szóval léphetünk vissza.
Az assembler, Forth, és a fordított lengyel jelölés
Mint a Forth része, az assembler is a fordított lengyel jelölés elvén dolgozik, amely szerint az operandusok (paraméterek) megelőzik az operációt (műveletet).
A Z80 regiszterek konstansként vannak definiálva, a többi utasítás pedig olyan szóként működik, amely a paramétereit a veremről szerzi meg, a helyes műveleti kód előállításához, majd pedig ezt a kódot fordítja be a következő szabad szótárbeli memóriahelyre. A regiszterek, és feltételkódok 16-bites kostansként vannak definiálva, a felső (magasabb helyértékű) bájt tartalmazza regiszter típusát (8-bites, 16-bites), az alsó bájt pedig azt, hogy pontosan melyik regisztert kell a műveletnél (az előbb leírt formában) felhasználni. A típus bájt értékei a hexadecimális C000 felett vannak.
A regiszter konstansok és értékeik (hexadecimálisan):
|
B | F000 |
|
(BC) | F800 |
|
C | F001 |
|
(DE) | F810 |
|
D | F002 |
|
I | F807 |
|
E | F003 |
|
R | F80F |
|
H | F004 |
| |
|
|
L | F005 |
|
BC | E000 |
|
(HL) | F006 |
|
DE | E001 |
|
A | F007 |
|
HL | E002 |
|
(IX+) | F606 |
|
AF | E004 |
|
(IX-) | F706 |
|
IX | EE02 |
|
(IY+) | F406 |
|
IY | EC02 |
|
(IY-) | F506 |
|
SP | E003 |
A feltételkódok (a feltételes vezérlésátadó utasításokhoz) szintén konstansok. Az értékek a következőképpen alakulnak:
|
NC | F000 |
|
C | F001 |
|
NZ | F002 |
|
Z | F003 |
|
PO | F004 |
|
PE | F005 |
|
P | F006 |
|
M | F007 |
Látható, hogy az értékek megegyeznek a regisztereknél definiáltakkal. A IX és IY regiszterek a következőképpen használhatók A Z80 (IY+d) ill. (IX-d) hivatkozások megfelelnek a (IY+) és (IX-) kódoknak olyan formában, hogy az eltolás (displacement) megelőzze a kódot. Például az
LD A,(IY+10)
utasítás a Forth-assemblerben a
10 (IY+) A LD,
szekvenciának felel meg.
Az utasításkészlet
Az utasítások a Zilog Z80 által használt mnemonikokat követik, persze a fordított lengyel jelölésnek megfelelően. Itt következnek az utasítások (Z80 formában, és a megfelelő Forth írásmódban):
|
Z80 |
Forth | |
Z80 |
Forth |
|
ADC A,r |
r A ADC, | |
IND | IND, |
|
ADC A,n |
n A ADC, | |
INDR |
INDR, |
|
ADC HL,rr |
rr HL ADC, | |
INI | INI, |
|
ADD A,r |
r A ADD, | |
INIR |
INIR, |
|
ADD A,n |
n A ADD, | |
JP (HL) |
HL JP(), |
|
ADD HL,rr |
rr HL ADD, | |
JP (IX) |
IX JP() |
|
ADD IX,rr |
rr IX ADD, | |
JP (IY) |
IY JP() |
|
ADD IY,rr |
rr IY ADD, | |
JP nn |
nn JP() |
|
AND r |
r AND, | |
JP cc,nn |
nn cc ?JP, |
|
AND n |
n AND, | |
JR d |
addr JR, |
|
BIT b,r |
r b BIT, | |
JR cc,d |
addr cc ?JR, |
|
CALL nn |
nn CALL, | |
LD (BC),A |
A (BC) LD, |
|
CALL cc,nn |
nn cc ?CALL, | |
LD (DE),A |
A (DE) LD, |
|
CCF | CCF, |
|
LD R,A |
R A LD, |
|
CP r |
r CP, | |
LD I,A |
A I LD, |
|
CP n |
n CP, | |
LD A,(BC) |
(BC) A LD, |
|
CPD | CPD, |
|
LD A,(DE) |
(DE) A LD, |
|
CPDR |
CPDR, | |
LD A,R |
A R LD, |
|
CPI | CPI, |
|
LD A,I |
I A LD, |
|
CPIR |
CPIR, | |
LD r,r' |
r' R LD, |
|
CPL | CPL, |
|
LD r,n |
n r LD, |
|
DAA | DAA, |
|
LD (nn),A |
A nn () LD, |
|
DEC r |
r DEC, | |
LD (nn),HL |
HL nn () LD, |
|
DEC rr |
rr DEC, | |
LD (nn),DE |
DE nn () LD, |
|
DI | DI, |
|
LD (nn),SP |
SP nn () LD, |
|
DJNZ d |
addr DJNZ, | |
LD (nn),BC |
BC nn () LD, |
|
EI | EI, |
|
LD rr,nn |
nn rr LD, |
|
EX (SP),HL |
HL SP () EX, | |
LD (rr),nn |
nn rr () LD, |
|
EX (SP),IX |
IX SP () EX, | |
LD SP,HL |
HL SP LD, |
|
EX (SP),IY |
IY SP () EX, | |
LD SP,IX |
IX SP LD, |
|
EX AF,AF' |
AF' AF EX, | |
LD SP,IY |
IY SP LD, |
|
EX DE,HL |
HL DE EX, | |
LDD | LDD, |
|
EXX | EXX, |
|
LDDR |
LDDR, |
|
HALT |
HALT, | |
LDI | LDI, |
|
IM n |
n IM, | |
LDIR |
LDIR, |
|
IN A,(C) |
C A IN(), | |
NEG | NEG, |
|
IN A,(n) |
n A IN(), | |
NOP | NOP, |
|
INC r |
r INC, | |
OR r |
r OR, |
|
INC rr |
rr INC, | |
OR n |
n OR, |
|
OTDR |
OTDR, | |
RR r |
r RR, |
|
OTIR |
OTIR, | |
RRC r |
r RRC, |
|
OUTD |
OUTD, | |
RRD | RRD, |
|
OUTI |
OUTI, | |
RST n |
n RST, |
|
POP rr |
rr POP, | |
SBC A,r |
r A SBC, |
|
PUSH rr |
rr PUSH | |
SBC A.n |
n A SBC, |
|
RES b,r |
r b RES, | |
SBC HL,rr |
rr HL SBC, |
|
RET | RET, |
|
SCF | SCF, |
|
RET cc |
cc ?RET, | |
SET b,r |
r b SET, |
|
RETI |
RETI, | |
SLA r |
r SLA, |
|
RETN |
RETN, | |
SRA r |
r SRA, |
|
RL r |
r RL, | |
SRL r |
r SRL, |
|
RLA | RLA, |
|
SUB r |
r SUB, |
|
RLC r |
r RLC, | |
SUB n |
N SUB, |
|
RLCA |
RLCA, | |
XOR r |
r XOR, |
|
RLD | RLD, |
|
XOR n |
N XOR, |
A jelölések magyarázata:
-
r = 8-bites regiszter pL. A
-
rr = 16-bites regiszter pL. DE
-
n = 8 bites adat pL. 240, ha a számrendszer decimális
-
nn = 16-bites adat
- cc = feltételkód pl. PO
-
b = bitszám pl. 4 - adott regiszter 4.bitjének befolyásolásához
-
d = kettes komplemensű 8 - bites eltolás - relatív ugrásokhoz.
Amint az látható, a Forth-assemblerben a szavak végét vessző (,) jelzi. Mindez a következőkre vezethető vissza:
-
Forth konvenció, hogy azok a szavak amelyek a szótárba fordítanak, vesszővel végződjenek (pl. C,),
-
a vessző jól elkülöníti az assembler-szavakat a Forth-szavaktól, s így nem lehet őket összekeverni (pl. XOR és XOR,),
-
az általános Forth-assembler kód tartalmazhat több utasítást is egy adott soron belül (szemben a konvencionális assemblerek egy utasítás - egy sor szemléletével). A vessző a szavak végén az egyes utasítások szétválasztását (elkülöníthetőségét) segíti.
Forth-assembler szavak definiálása:
CODE név ... END-CODE
vagy
:név ... :CODE ... END-CODE
ahol a név természetesen a szó nevét jelenti a ... pedig assembler-, illetve (a második forma első részében) Forth-szavakat jelent.
Az IS-Forth a következő regisztereket használja:
SP - paraméter verem (a legfelső két elem külön regiszterben !),
IY - visszatérési verem mutató,
IX - a belső interpreter (NEXT) címe,
HL' - interpreter pointer (a végrehajtásra következő szó címe),
DE' - a végrehajtandó szó CFA címe,
HL, DE - a paraméter verem legfelső két eleme.
5.2. Változók és konstansok
Valamennyi változó ugyanúgy működik: a veremre teszi azt a címet, ahol a változó értéke van. Így talán nem meglepő, hogy változóink kódmezői mind ugyanazt a címet tartalmazzák. Annál meglepőbb, hogy a rendszerváltozóké (BLK, DPL stb.) nem ugyanaz. Az ilyen különleges változók:
|
HLD | Számok karaktersorozattá konvertálásakor az utoljára konvertált karakter címét tartalmazza. |
|
R# | Az editor használja a kurzorpozíció tárolására.
|
| CSP |
A veremmutató értékének átmeneti tárolására szolgál Fordítás alatt hibaellenőrzésre használjuk. |
|
FLD | |
|
DPL | Szám tizedespont utáni jegyeinek számát tartalmazza. Ha nem volt tizedespont, az értéke -1. |
|
BASE | Az input és output konverziók alapszáma. |
|
STATE | A rendszer fordítási vagy végrehajtási állapotát jelzi. A nem 0 érték fordítást jelent. |
|
CURRENT | |
|
CONTEXT | Egy mutatót tartalmaz a kereső szótárra. |
|
SCR | Az aktuális (LIST-el legutoljára listázott) kernyő számát tartalmazza. |
|
OUT | Értékét az EMIT növeli. A programozó változtathatja vagy vizsgálhatja, hogy a kiírás formátumát vezérelje. |
|
BLK | Az éppen interpretált blokk számát tartalmazza. Ha 0, akkor az interpreter a parancspufferből dolgozik. |
|
VOC-LINK | Az utoljára definiált szótárra tartalmaz mutatót. A szótárnevek össze vannak láncolva. |
|
DP | A szótár fölötti első szabad memóriacím. Értéke a HERE szóval olvasható, az ALLOT szóval változtatható. |
|
FENCE | Azt a címet tartalmazza, amelynél alacsonyabb címről a FORGET nem törölhet (a szótár védett). |
|
TIB | A parancspuffer címét tartalmazza. |
|
R0 | A viremmutató kezdeti értékét tartalmazza. |
|
S0 | A veremmutató kezdeti értékét tartalmazza. |
A rendszerváltozók (USER, ejtsd: júzer változók) egy táblázatban vannak. A konstansok kódmezője is egyforma: mind arra a kódra mutat, amely a paramző tartalmát a veremre teszi. Így egy szótári szó kódmezőjéből megállapíthatjuk, hogy kettőspontos szóról, primitíváról vagy egyébről van szó.
5.3. Az EXECUTE
Az
EXECUTE ( kódmezőcím - - - - )
az a szó, amely végrehajtja a vermen megadott kódmezőcímű másik szót.
5.4. Hibakezelés
(ABORT)
A hibakezelőt aktivizálja, a kővetkező formában használható:
(ABORT) név (Ahol a név egy korábban definiált szót jelent)
Bekapcsolt hibakezelés esetén a név végrehajtása után a rendszer végrehajt egy ABORT utasítást: törli az adatvermet, s várja a további utasításokat anélkül, hogy bármilyen üzenetet adna, és a kurzort pozícionálná. A név végrehajtás után a hibakód az adatveremre kerül Ezzel mintegy saját hibakezelő rutinokat írhatunk (esetleg szavanként, vagy alkalmazásonként külön-külön is). Kikapcsolni a hibakezelést az
(ABORT) ERROR
beírásával lehet.
6. Azonnali szavak
6.1. Amikor az interpreter fordít
A kettőspontos szódefiníciókat bevezető : szó létrehozza az új szó név-, kód- és láncmezőjét, majd ún. fordítási állapotba teszi az interpretert. Ez annyit jelent, hogy az interpreter a befolyam szavait nem hajtja végre, hanem előkeresi a kódmezőcímüket és a szóval tárolja a HERE címen (az éppen létrejövő szó paramzőjében).
Hogy a befolyamban talált szavakat az interpreter végrehajtja vagy lefordítja, az a STATE rendszerváltozó (USER változó) értékétől függ. Ha a STATE értéke nem 0, akkor a befolyam szavai lefordítódnak. Ennek megfelelően, ha a STATE 0, végrehajtási, ha nem, fordítási állapotról beszélünk. A STATE értékét (többek között) a definíciókat bevezető . és a befejező ; szó állítja.
6.2. Amikor az interpreter mégsem fordít
Nézzünk egy meglehetősen közönséges definíciót:
: COUNT DUP 1+ SWAP C@ ;
A fentiek szerint a COUNT paramzője így néz ki:
DUP kódmezőcíme |
1+ kódmezőcíme |
SWAP kódmezőcíme |
C@ kódmezőcíme |
;S kódmezőcíme |
Egészítsük most ki ugyanezt a definíciót egy kommenttel:
: COUNT ( ff-cím - - - - cím hossz ) DUP 1+ SWAP C@ ;
A fentiekből az következne, hogy a második COUNT paramzőjében megjelenik a
( szó kódmezőcíme (hiszen a ( szó feltűnésekor a STATE nem 0, a rendszer fordítási állapotban van). A józan ész viszont azt súgja, hogy a két definíció eredménye azonos kell, hogy legyen, ha egyszer csak egy kommentben térnek el egymástól. A józan észnek van igaza: a fordítási állapotban sem minden szó fordítódik le. A szabályt erősítő kivételek az azonnali (immediate, ejtsd: immediét) szavak.
Az azonnali szavak akkor sem fordítódnak le, mikor az interpreter fordítási állapotban van; valahányszor az interpreter felleli őket, azonnal végrehajtódnak.
A ( egy azonnali szó. Azonnali szavakat magunk is írhatunk; csak az kell hozzá, hogy a szó definíciója után a friss szót az
IMMEDIATE
szóval azonnalivá tegyük.
6.3. Literálok
A literálok azok a számok, amelyeket a definícióban adunk meg; ezeket az interpreter beírja a paramzőbe. Például a
: .HAT 6 . ;
Előfordulhat, hogy a szódefinícióban használandó érték egy művelet eredménye; mondjuk, azt akarjuk felhasználni, hogy egy nap perceinek száma 60*24. Ezt ugyan ki lehet számolni előre, de akkor nem látszik rajta, hogy mi ez és hogyan számoltuk ki; a szorzást be is lehet írni a definíció szövegébe, de akkor minden egyes futáskor végrehajtódik, ami időpocsékolás. Ehelyett azt is megtehetjük, hogy a fordítási állapotot a
[
szóval megszüntetjük, előállítjuk a vermen a kívánt értéket, és a
]
szóval visszatérünk a fordítási állapotba. A vermen levő értéket a
LITERAL
szó fogja literálként a paramzőbe fordítani:
: PERCEK [ 60 24 * ] LITERAL . ." perces egy nap" ;
A LITERAL szó természetesen azonnali. Ha nem definícióban használjuk, a LITERAL nem csinál semmit.
6.4. Azonnali szavak elhalasztása a [COMPILE])
Ismerkedjünk meg egy új szóval:
[COMPILE]
Lefordítja a mögötte álló azonnali szót (amely a [COMPILE] nélkül nem fordítódna le, hanem végrehajtódna).
7. Az IS-FORTH "különlegességei"
7.1. Kapcsolat az EXOS-al
Az IS-FORTH-ból elérhetjük valamennyi EXOS változót. Erre a következő két szó szolgál:
|
E! | ( n e - - - - ) |
Eltarolja n értéket az e EXOS változóba. |
|
E@ | ( e - - - - ) |
A stack-re másolja az e EXOS változó értékét. (Ugyanerre a célra szolgál az ASK szó.) |
A kővetkező EXOS voltozókat egyszerűbben -a nevükre hivatkozva- is kezelhetjük:
BUFFER
STOP
BAUD
MODE
COLORS
X
BORDER
REM2
|
TIMER
SPEAKER
FORMAT
COLOURS
STATUS
Y
REM1
BIAS |
Az EXOS változók állítására rendelkezésre állnak a következő szavak is:
ON - bekapcsolás
OFF - kikapcsolás
TOGGLE - átkapcsolás
Példák, felhasználva a E! és E@ szavakat:
|
0 BORDER E! |
Fekete színű keretet állít be. |
|
STATUS ON | Látható lesz a státuszsor. |
|
REM1 TOGGLE |
Magnó távvezérlés |
Mindezek mellett az I/O csatornák kezelését is kezünkbe vehetjük (esetleges átirányítás céljából). Erre a
#EDITOR
#GRAPHICS
#TEXT
#STATUS
szavak használhatók. Például a 101 #GRAPHICS átirányítja a grafikus csatornát a 101-es számra. Az
ATTRIBUTE
HIRES
LORES
TEXT
szavak az eredeti értékeket állítják viasza az átirányítási táblában.
Csatornakezelésre szolgálnak a
GET ( ch - - - - n )
PUT ( n ch - - - - )
szavak is, ahol ch a csatorna száma, n pedig a kiküldendő érték.
Az átirányítási táblázat alapértékei, valamint az őket használó csatornák a kővetkezők:
101
102
103
104
105
106
107
108 |
VIDEO:
VIDEO:
SOUND
PRINTER:
KEYBOARD:
TAPE: vagy DISK:
VIDEO:
EDITOR:
| (grafikus lap)
(szöveges lap)
(hangkezelő)
(nyomtató)
(billentyűzet)
(Az EDIT végrehajtása alatt)
(Az EDIT végrehajtása alatt) |
A FORTH rendszerből indíthatunk más rendszerbővítőket is:
EXT (addr - - - - )
Az adott címen levő parancs-sztringet (az első byte a név hossza) az EXOS kapja meg, s elindítja azt, amennyiben lehetséges.
7.2. Grafika az IS-FORTH-ban
Az IS-FORTH-ban az IS-BASIC-hez hasonló (igen széles) lehetőségek nyílnak meg előttünk a grafikai megvalósításban. Szerencsére a parancsok ugyanazok mint a BASIC-ban, csak a "fordított" formához kell hozzászoknunk. A rendelkezésre álló videó üzemmódok a BASIC-ben megismertek, tehát 2, 4, 16, 256 színes HIRES vagy LORES felbontású videólapokat nyithatunk. Nyissunk meg például egy 4 színes nagyfelbontású videólapot:
4 HIRES GRAPHICS
További szavak (a teljesség igénye nélkül):
PALETTE ( n1 n2 n3 n4 n5 n6 n7 n8 - - - - )
A videólap színpalettáját állíthatjuk be. Az n1-n8 értékek a színek kódjai. Bármilyen színüzemmódot állítunk be, a szó mindig 8 kódot vár a veremből.
INK ( n - - - - )
A tinta színét n értékre állítja be.
PLOT ( x y - - - - )
Az aktuális tintaszínnel pontot rajzolunk a videólap x y pozíciójába. A rajzolósugár x y pozícióban marad.
Példa: 10 10 PLOT
DRAW ( x y - - - - )
A rajzolósugár aktuális pozíciójából vonalat húz x y pozícióba. A rajzolósugár x y pozícióban marad.
Példa: 500 100 PLOT
ELLIPSE ( r1 r2 - - - - )
r1 r2 sugarú ellipszis (vagy kör, ha r1 = r2) rajzolása. A z ellipszis (kör) középpontja a rajzolósugár aktuális pozíciója.
A következő nyolc színre nemcsak kódszámukkal, hanem nevükkel is hivatkozhatunk:
BLACK - fekete
BLUE - kék
CYAN - világoskék
GREEN - zöld
MAGENTA - lila
RED - piros
WHITE - fehér
YELLOW - sárga
A színek "kikeverésére" rendelkezésre áll a BASIC-ből szintén ismerős:
RGB ( n1 n2 n3 - - - - )
7.3. Egyéb szavak
|
FREE |
( - - - - n ) |
A szabad memória nagyságát adja meg bájtban (ez a terület szolgál a stack-nak és a szótárnak). |
|
INFO |
( - - - - ) |
Az aktuális memória foglaltságát jelzi ki. |
|
JOY |
( n1 - - - - n2 ) |
A botkormányt olvassa le. (n1 = 0 - belső, n1 = 1 - EXT1, n1 = 2 - EXT2) A beolvasott bájt bitjei (b4 ... b0) tartalmazzák az irányra és a tűzgombra vonatkozó adatokat. A bitek növekvő sorrendben a bal, jobb, fel, le irányt és a tűzgomb lenyomását jelentik. |
Az üzemmódok
A fejlesztést, majd a használatot a
SLOW (- - - - )
illetve
FAST (- - - -)
üzemmódok segítik A SLOW utasítás kiadása után a hibakövetés állandó jelleggel megtörténik. Ezzel szemben a FAST "üzemmód" már a kész programok futtatására szolgál, ekkor a hibafigyelés kikapcsolt állapotú, s ez jelentősen gyorsítja a programok futását. A rendszer indítása után a FAST üzemmód az alapértelmezésű.
Az IS-FORTH szójegyzék ABC sorrendben tartalmazza az összes IS-FORTH szót.
A szójegyzéknek is érdemes átolvasni, mivel ebben a leírásban nem említett szavakkal is megismerkedhetünk!

 Az alábbi "rövid ismertető" a FORTH programozási nyelv, pontosabban annak - az Intelligent Software Ltd megvalósított- IS-FORTH rejtelmeibe kívánja bevezetni az olvasót. Az ismertető nem teljes, mindössze arra vállalkozik, hogy ízelítőt adjon a FORTH rejtelmeiből. A leírás Adorján Noémi - FORTH lépésről lépésre című könyve ( Műszaki könyvkiadó - 1990) alapján készült, az IS-FORTH "nyelvjárásához" igazítva.
Az alábbi "rövid ismertető" a FORTH programozási nyelv, pontosabban annak - az Intelligent Software Ltd megvalósított- IS-FORTH rejtelmeibe kívánja bevezetni az olvasót. Az ismertető nem teljes, mindössze arra vállalkozik, hogy ízelítőt adjon a FORTH rejtelmeiből. A leírás Adorján Noémi - FORTH lépésről lépésre című könyve ( Műszaki könyvkiadó - 1990) alapján készült, az IS-FORTH "nyelvjárásához" igazítva.